刚刚,DeepSeek开源了其面向OCR场景的专用模型DeepSeek-OCR 2,技术报告同步发布。这一模型是对去年DeepSeek-OCR模型的升级,其采用的新型解码器让模型看图、读文件的顺序更像人,而不是像机械的扫描仪。
简单来说,以前的模型阅读模式是从左上到右下,地毯式扫一遍图片,DeepSeek-OCR 2则能够理解结构,按结构一步步读。这种新的视觉理解模式,让DeepSeek-OCR 2可以更好地理解复杂的布局顺序、公式和表格。
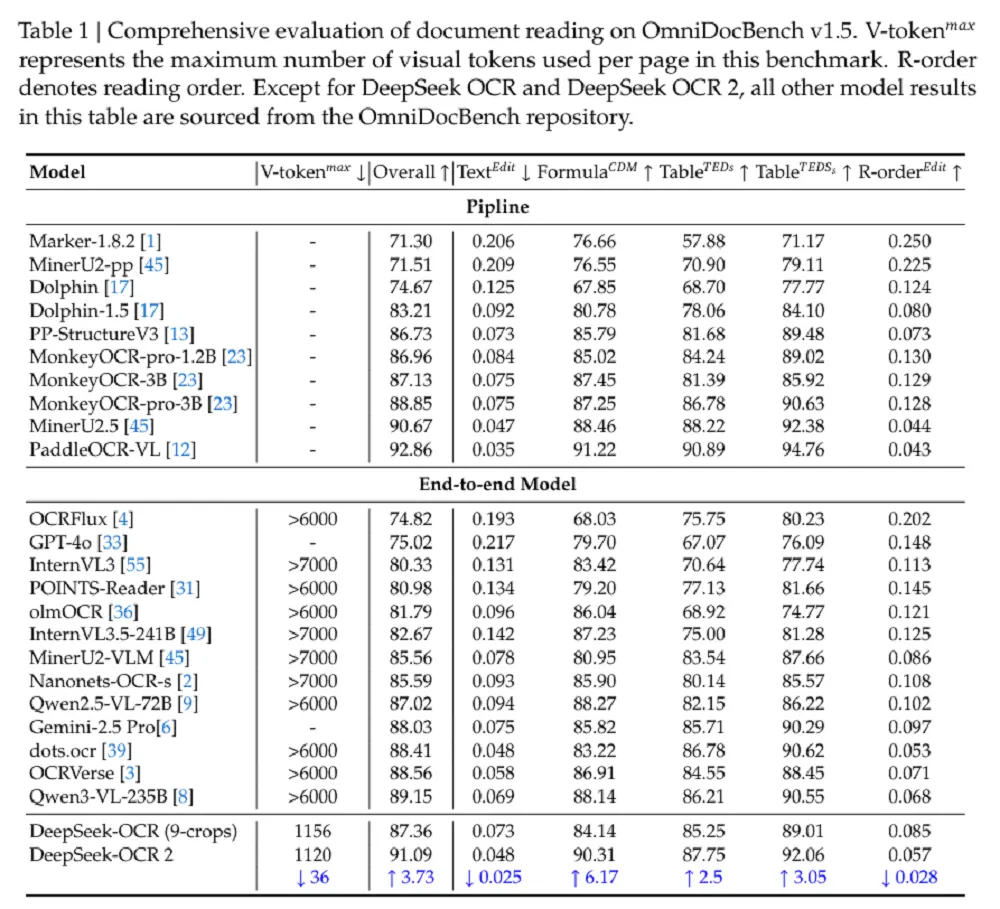
在文档理解基准测试OmniDocBench v1.5上,DeepSeek-OCR 2拿到了91.09%的得分,在训练数据和编码器都不变的前提下,较DeepSeek-OCR提升了3.73%。与其他端到端的OCR模型相比,这已经是SOTA成绩,但其表现要略逊于百度的PaddleOCR-VL(92.86%)OCR管线。
同时,在相似的视觉token预算下,DeepSeek-OCR 2在文档解析方面的编辑距离(编辑为正确文本所需的工作量)低于Gemini-3 Pro,这证明DeepSeek-OCR 2在确保优越性能的同时保持了视觉token的高压缩率。
DeepSeek-OCR 2兼具双重价值:既可作为新型VLM(视觉语言模型)架构进行探索性研究,也能作为生成高质量预训练数据的实用工具,服务于大语言模型的训练过程。
论文链接:
https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
开源地址:
https://github.com/deepseek-ai/DeepSeek-OCR-2?tab=readme-ov-file
01.
大模型不懂复杂文件结构?
先观察全局再阅读便可解决
从架构上来看,DeepSeek-OCR 2继承了DeepSeek-OCR的整体架构,该架构由编码器和解码器组成。编码器将图像离散化为视觉token,而解码器根据这些视觉token和文本提示生成输出。
关键区别在于编码器:DeepSeek将此前的DeepEncoder升级为DeepEncoder V2,它保留了原有的所有能力,但把原本基于CLIP的编码器换成基于LLM的,同时通过新的架构设计引入了因果推理。
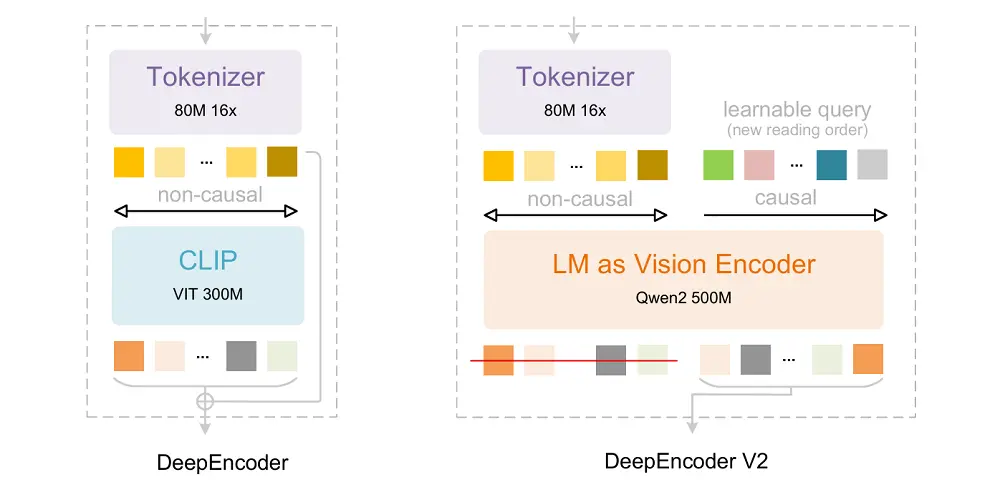
DeepEncoder V2关注的核心问题在于:当二维结构被映射为一维序列并绑定线性顺序后,模型在建模空间关系时不可避免地受到该顺序的影响。
这在自然图像中可能尚可接受,但在OCR、表格、表单等具有复杂布局的场景中,线性顺序往往与真实的语义组织方式严重不匹配,从而限制模型对视觉结构的表达能力。
DeepEncoder V2是如何缓解这一问题的?它首先采用视觉tokenizer对图像进行高效表示,通过窗口注意力实现约16倍的token压缩,在显著降低后续全局注意力计算与显存开销的同时,保持了充分的局部与中尺度视觉信息。
它并未依赖位置编码来规定视觉token的语义顺序,而是引入因果流查询(causal queries),通过内容感知的方式对视觉标记进行重排序与蒸馏。这种顺序不是由空间展开规则决定,而是由模型在观察全局视觉上下文后逐步生成,从而避免了对固定一维顺序的强依赖。
每个因果查询可以关注所有视觉token及先前查询,从而在保持token数量不变的前提下,对视觉特征进行语义重排序与信息蒸馏。最终,仅因果查询的输出被送入下游LLM解码器。
该设计本质上形成了两级级联的因果推理过程:首先,编码器内部通过因果查询对无序的视觉标记进行语义排序。随后,LLM解码器在此有序序列上执行自回归推理。
相较于通过位置编码强制施加空间顺序的做法,因果查询所诱导的顺序更贴合视觉语义本身,也就是符合人类阅读内容的正常习惯。
由于DeepSeek-OCR 2主要关注编码器改进,没有对解码器组件进行升级。遵循这一设计原则,DeepSeek保留了DeepSeek-OCR的解码器:一个具有约5亿活跃参数的3B参数MoE结构。
02.
OmniDocBench得分达91.09%
编辑距离低于Gemini-3 Pro
为了验证上述设计的有效性,DeepSeek进行了实验。研究团队分三个阶段训练DeepSeek-OCR 2:编码器预训练、查询增强和解码器专业化。
第一阶段使视觉tokenizer和LLM风格的编码器获得特征提取、token压缩和token重排序的基本能力。第二阶段进一步增强了编码器的token重排序能力,同时增强了视觉知识压缩。第三阶段冻结编码器参数,仅优化解码器,从而在相同的FLOPs下实现更高的数据吞吐量。
为评估模型效果,DeepSeek选择OmniDocBench v1.5作为主要的评估基准。该基准包含1355个文档页面,涵盖中英文的9个主要类别(包括杂志、学术论文、研究报告等)。
DeepSeek-OCR 2在仅使用最小的视觉标记上限(V-token maxmax)的情况下,达到了91.09%的性能。与DeepSeek-OCR基线相比,在相似的训练数据源下,它表现出3.73%的改进,验证了新架构的有效性。
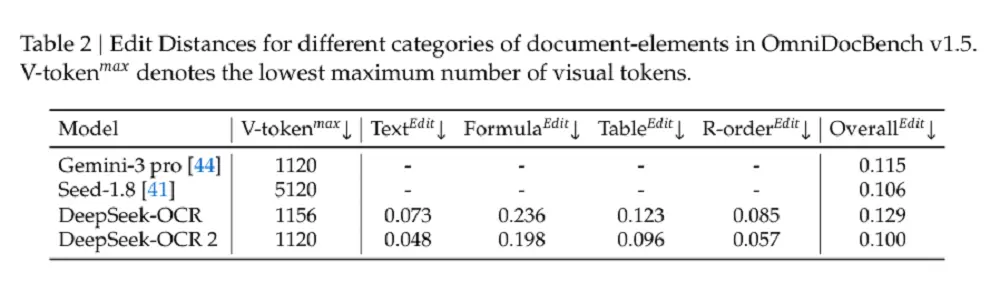
除了整体改进外,阅读顺序(R-order)的编辑距离(ED)也显著下降(从0.085降至0.057),这表明新的DeepEncoder V2可以根据图像信息有效地选择和排列初始视觉标记。
在相似的视觉标记预算(1120)下,DeepSeek-OCR 2(0.100)在文档解析方面的编辑距离低于Gemini-3 Pro(0.115),进一步证明新模型在确保性能的同时保持了视觉标记的高压缩率。
不过,DeepSeek-OCR 2也不是全能的。在文本密度超高的报纸上,DeepSeek-OCR 2识别效果没有其他类型的文本好。这一问题后续可以通过增加局部裁剪数量来解决,或者在训练过程中提供更多的样本。
03.
结语:或成新型VLM架构开端
DeepEncoder V2为LLM风格编码器在视觉任务上的可行性提供了初步验证。更重要的是,DeepSeek的研究团队认为,该架构具有演变为统一全模态编码器的潜力。这样的编码器可以在同一参数空间内压缩文本、提取语音特征和重组视觉内容。
DeepSeek称,DeepSeek-OCR的光学压缩代表了向原生多模态的初步探索,未来,他们还将继续探索通过这种共享编码器框架集成额外模态,成为研究探索的新型VLM架构的开端。