今天,是OpenAI的主场,同一天祭出两大杀器——GPT-5.1 Pro和GPT-5.1-Codex-Max。最强编码模型首次采用“压缩”机制,在数百万token上连续编程超24小时。AI圈一日一更的频率,真的是有点跟不住了....前两天,先是Grok 4.1、Gemini 3 Pro发布,今天OpenAI GPT-5.1 Pro也静默登场了!没有一篇博文,仅有两句话官宣。
众所周知,GPT-5.1主打“情商智商”双强,Pro无疑将这两大优势推向更高层次。
同一天,OpenAI全新王牌代码模型GPT-5.1-Codex-Max,已经在Codex平台正式上线了!

从命名上不难看出,它是基于GPT-5.1搭载,并在软件、工程、数学、研究等智能体任务专门训练。
由此,GPT-5.1-Codex-Max能力更强、反应更快,而且用起来更省token。
新模型是专为“长时间、高强度”的开发任务而设计。
就这么说吧,它能连续自主工作超24小时,一口气处理数百万token,直接交付成果的那种。

这恰恰印证了,Scaling Law还在永续。
这是因为,GPT-5.1-Codex-Max是OpenAI首个“原生支持压缩”机制的模型,可以跨越多个上下文工作。
这下,像项目重构、深度调试、多小时智能体循环这些任务,它都能稳稳接住。
目前,GPT-5.1 Pro已向所有Pro订阅用户推出。
GPT-5.1-Codex-Max已在Codex 中支持CLI、IDE 扩展、云端和代码审查使用,API接口也将很快上线。
2025年临近收官,AI终极对决一触即发,GPT-5.1 Pro与Gemini 3 Pro之间,胜负之手将落于谁家?

OpenAI最强编程模型
这次的GPT-5.1-Codex-Max,那可是在“真实战场”上炼出来的!
诸如在PR创建、代码审查、前端开发、问答等工程师常见任务中,全部做过专门训练。
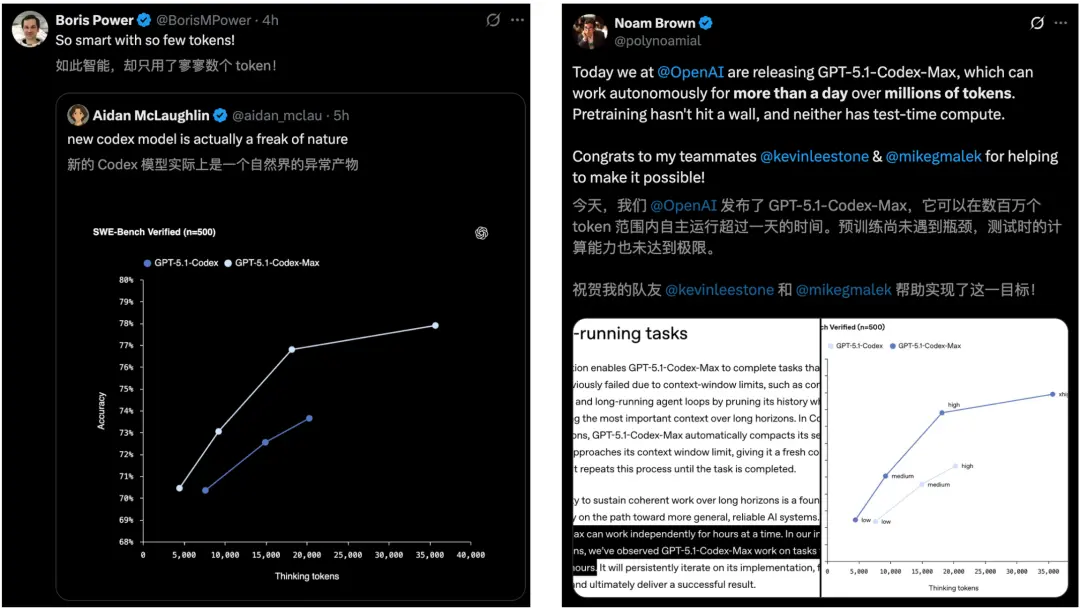
在多项前沿编码评测中,它都轻松超越了OpenAI此前所有模型。
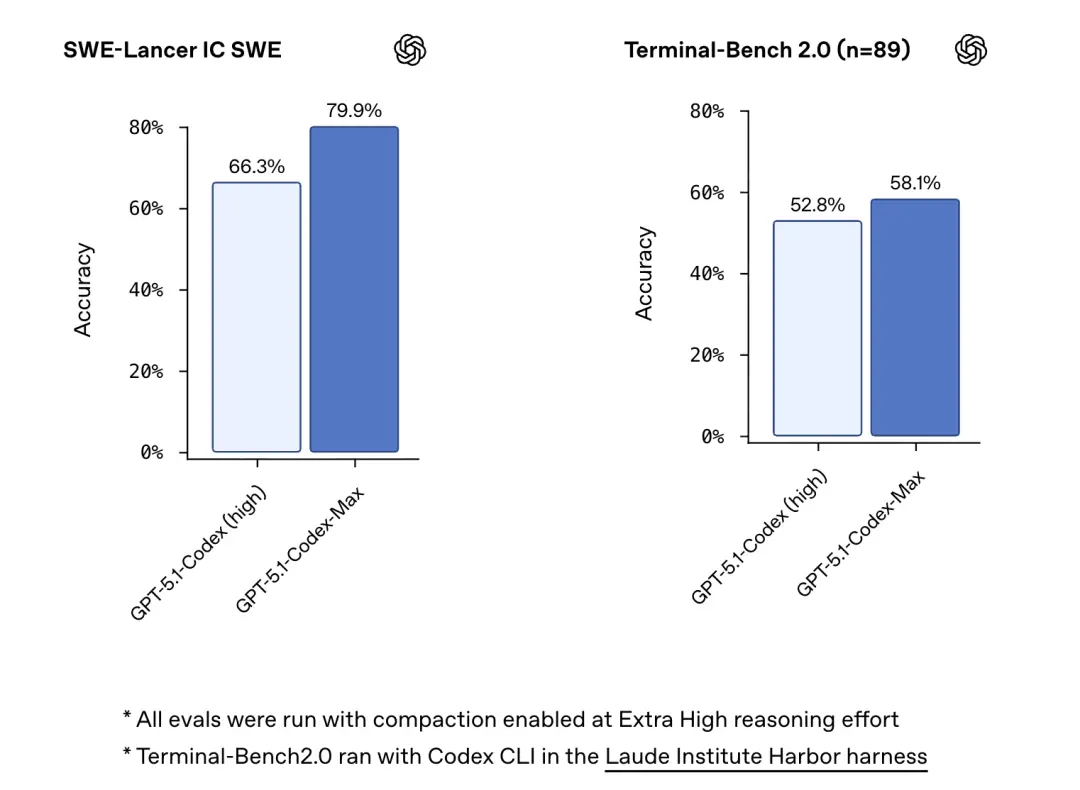
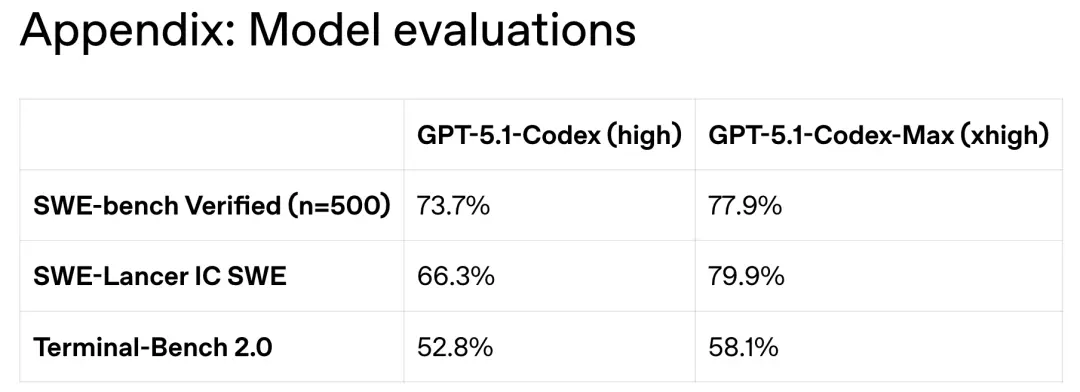
还有在SWE-bench Verified上的评估结果中,GPT-5.1-Codex-Max拿下了77.9%的高分。
GPT-5.1-Codex-Max不仅跑分高,实际体验更是大升级!
它是OpenAI首个可以在Windows环境中运行的模型,训练中还针对Codex CLI协作场景做了优化,更好用了。
思考token暴降30%
不仅如此,GPT-5.1-Codex-Max用起来也更省钱了。
在同样“medium”(中等)推理强度下,它不光表现比GPT-5.1-Codex更好,而且思考过程所用的token量减少约30%。
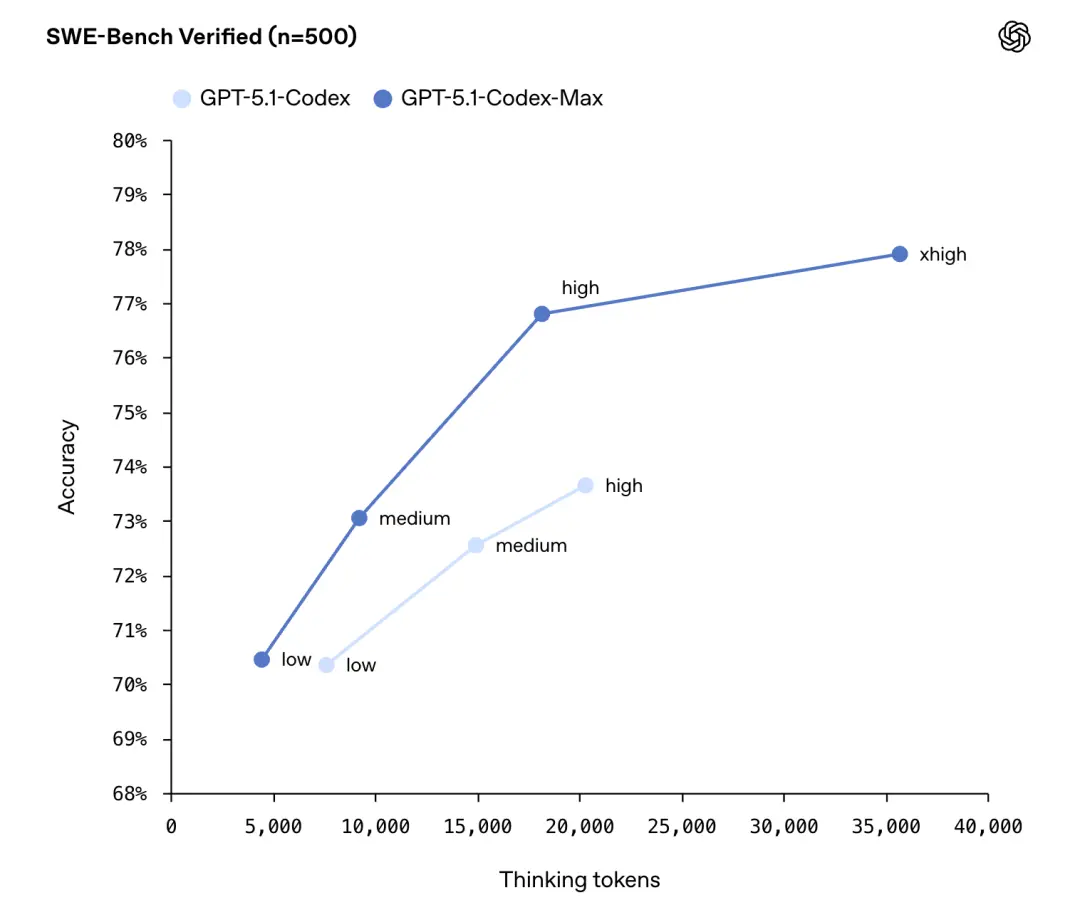
对于不敏感于延迟的任务,新增的“Extra High”(xhigh)推理强度,可花费更多时间获得优质答案。
不过,日常使用的话,OpenAI还是推荐medium。
token省下来了,这就意味着在实际开发中,成本可以大幅降低,可谓开发者的福音。
下面这些demo中,清晰呈现了GPT-5.1-Codex-Max和GPT-5.1-Codex使用token差异。即便是token减少,前者在前端设计中的功能和颜值都不输以往。
比如,让它们生成一个浏览器应用——即可交互的CartPole强化学习沙盒,需要包括小型策略梯度控制器、指标面板,以及一个SVG网络可视化器。
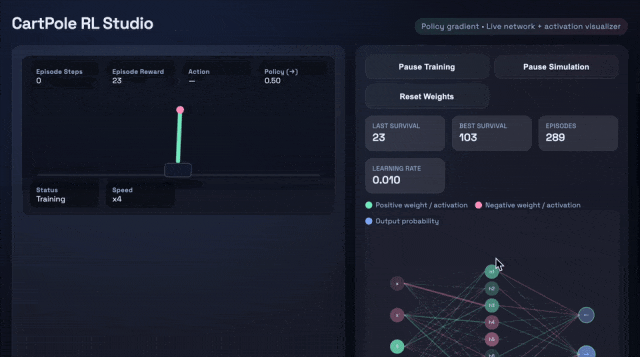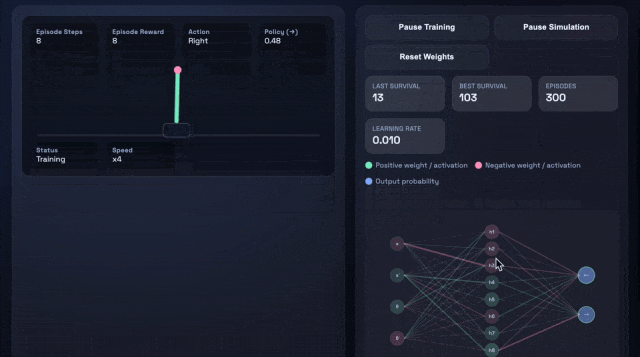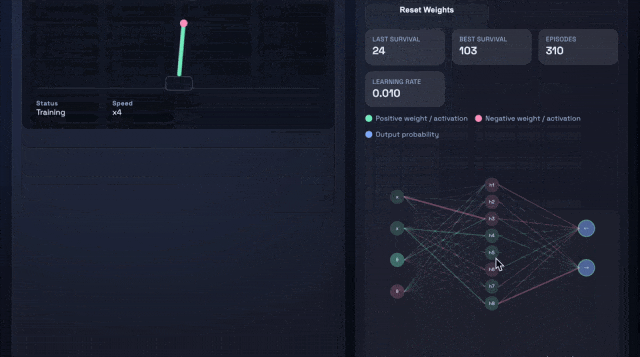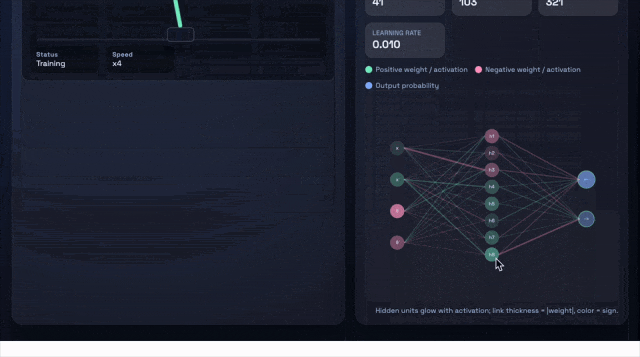
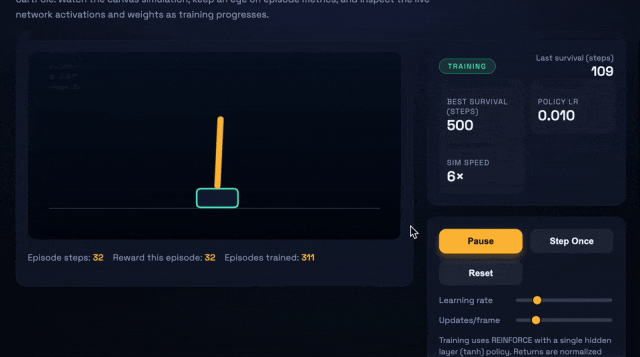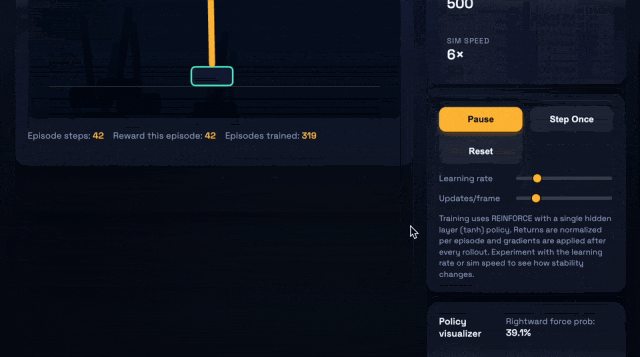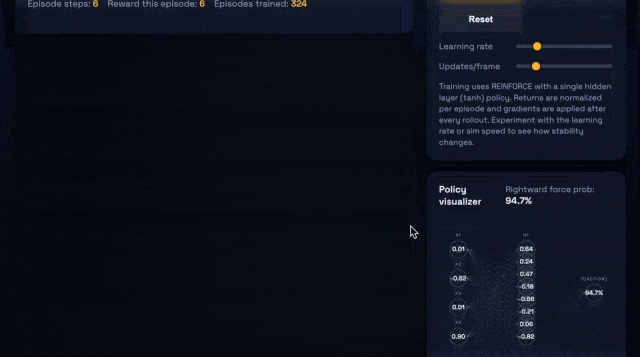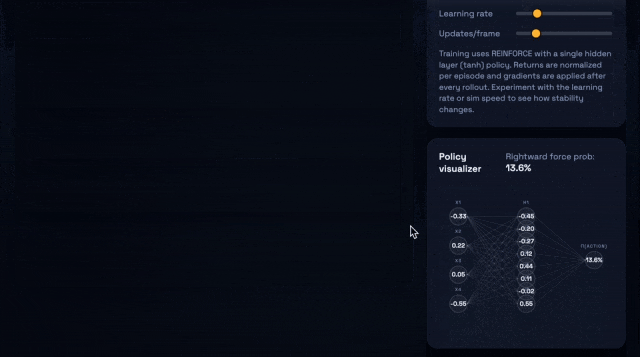
上:GPT-5.1-Codex-Max;下:GPT-5.1-Codex
GPT-5.1-Codex-Max仅用27k思考token完成了任务,而且代码更加精简。

这个demo要求的是,做一个太阳系引力井沙盒,需要可视化物体在2D引力势场中的运动,并支拖动平移视图、环绕观察场景。
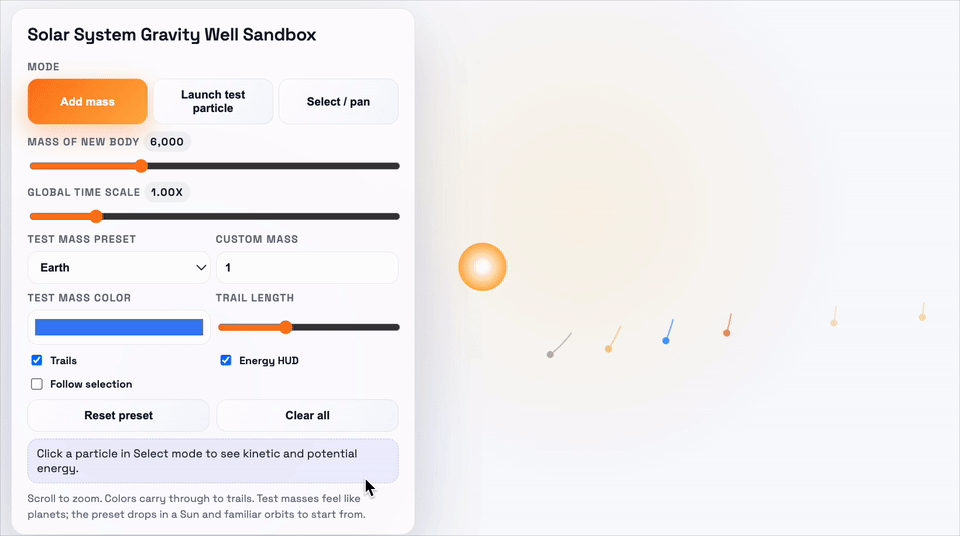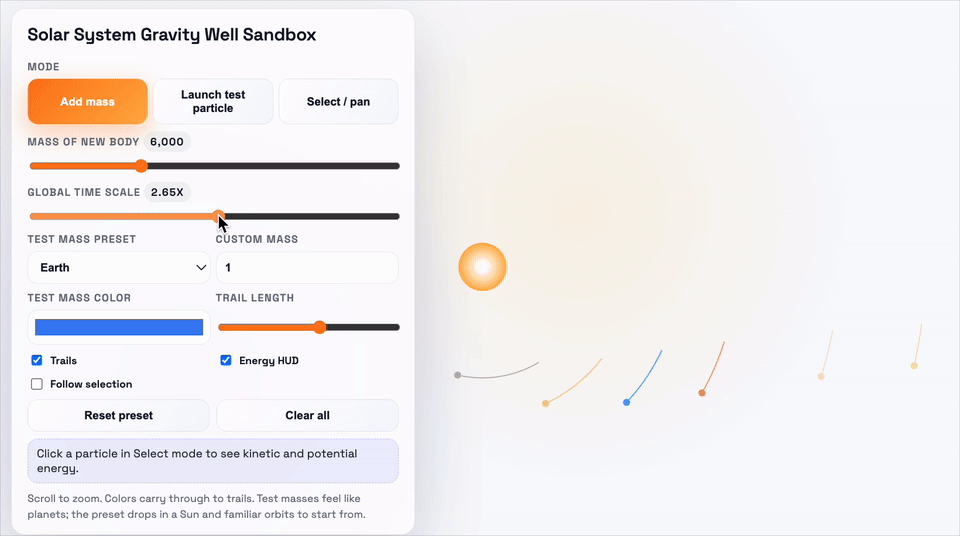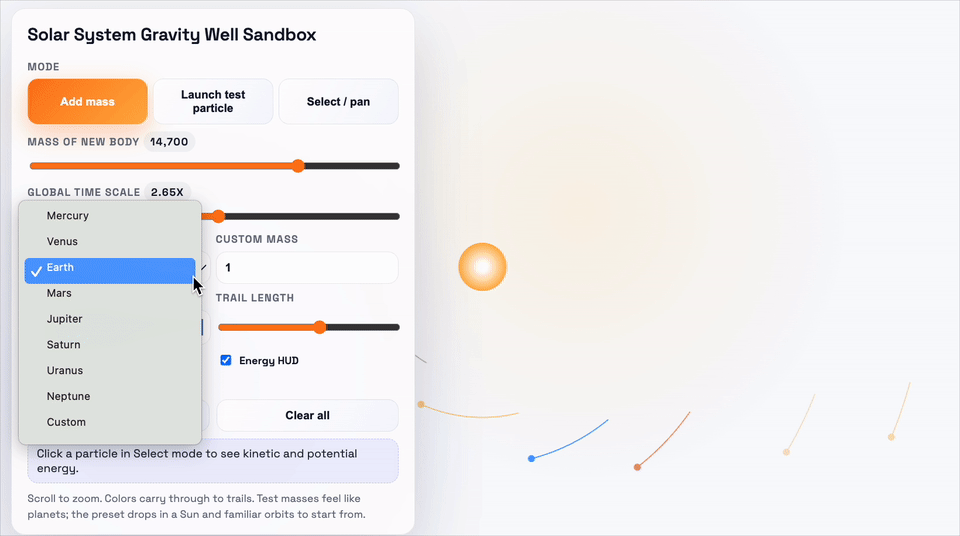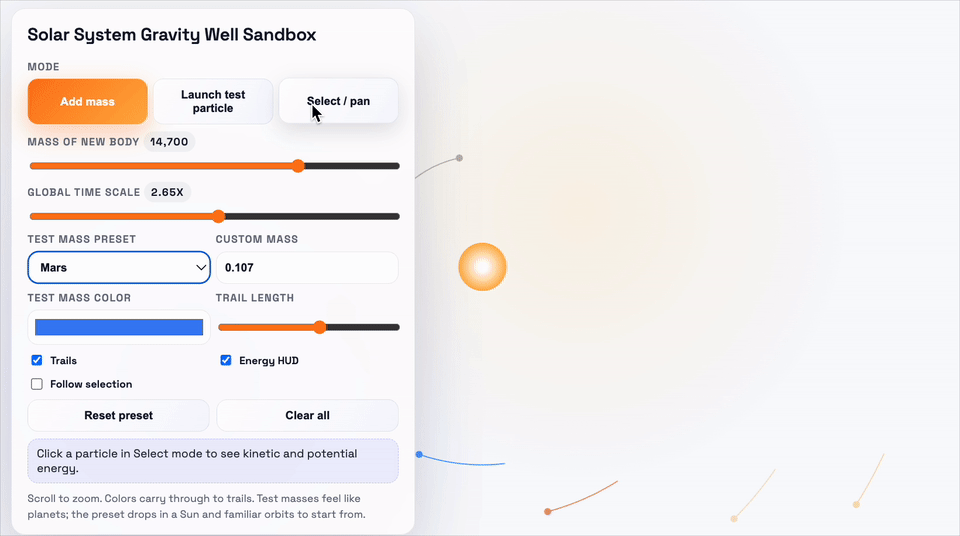
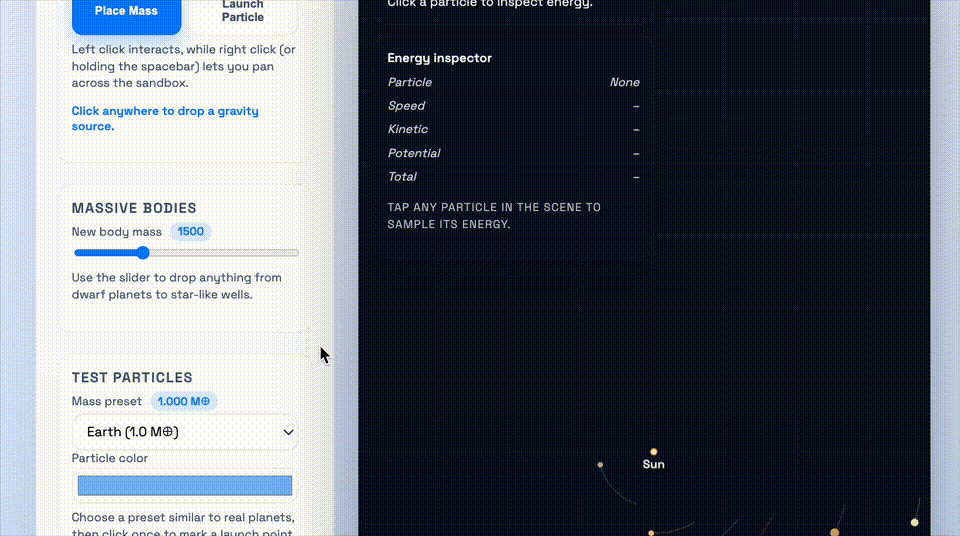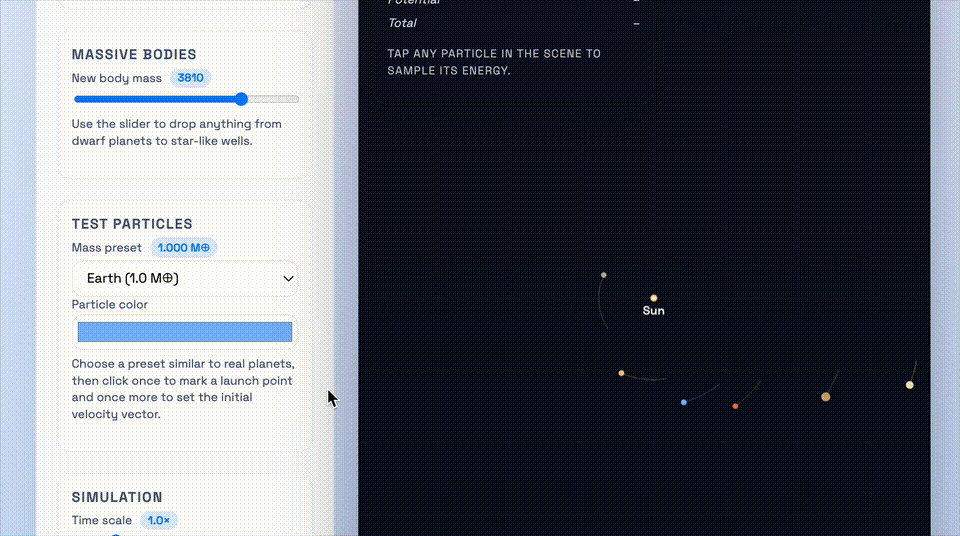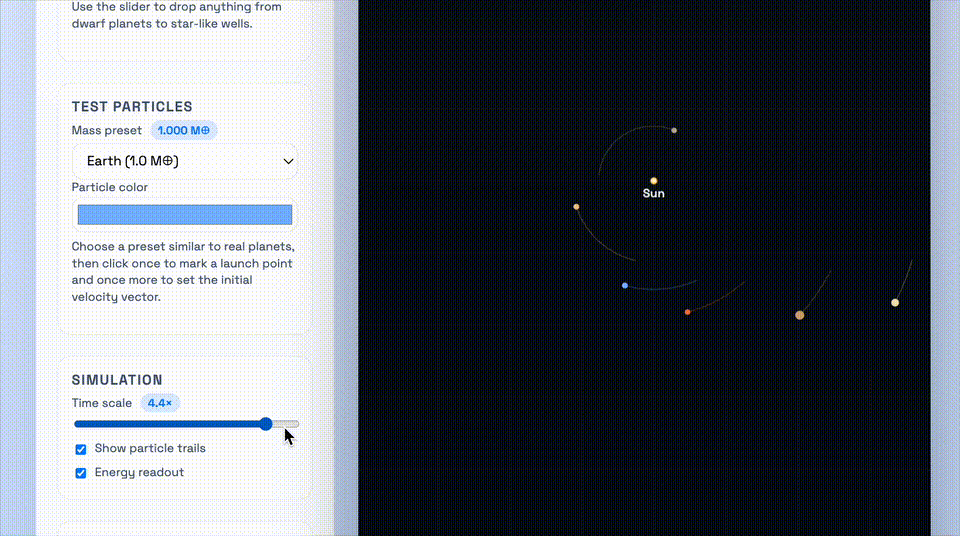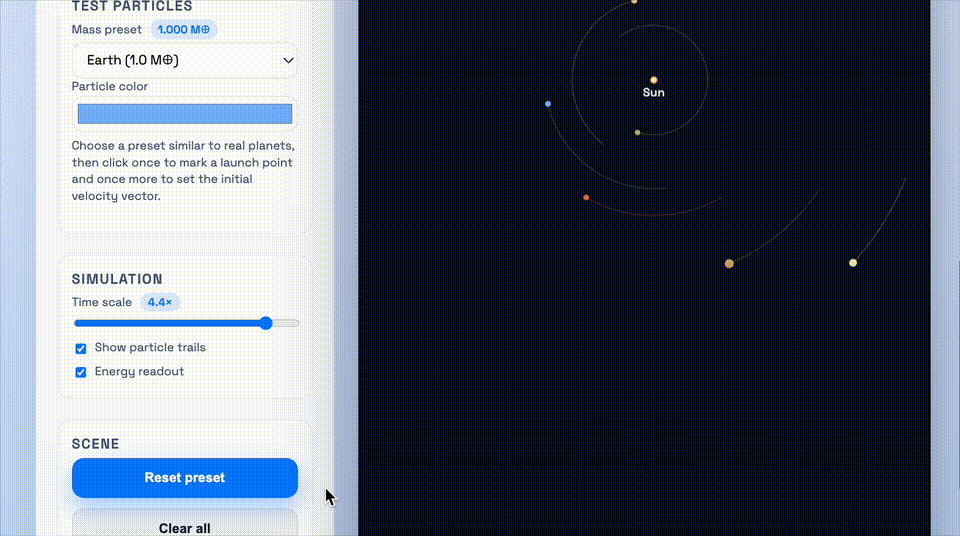
上:GPT-5.1-Codex-Max;下:GPT-5.1-Codex
GPT-5.1-Codex-Max同样用了更少的token,和更精炼的代码完成了任务。

GPT-5.1-Codex-Max这么强,是因为采用了一套全新机制。
狂跑一天,全是“压缩”
“压缩”机制让GPT-5.1-Codex-Max突破限制,处理那些因上下文太长而原本无法完成的任务。
比如,复杂重构和长时间智能体循环。
它会自动整理历史内容,筛选保留最关键的上下文,从而实现在长时间跨度内连贯性。
在Codex中,当接近上下文上限时,GPT-5.1-Codex-Max会自动执行会话压缩,刷新上下文,并多次重复这一过程直到任务完成。
下面这个案例中,GPT-5.1-Codex-Max正在自主重构Codex CLI的开源仓库。
可以看到,当上下文快满时,它会自动压缩释放空间,从而在不丢失进度情况下完成任务。
视频已经过剪辑和加速处理,以便更清楚地展示过程
内部测试显示,GPT-5.1-Codex-Max能连续自主工作超24小时。
在此期间,可以不断迭代实现、修复测试失败,并最终交付可用成果。
这种长时间、连贯的任务能力,是迈向更通用、更可靠AI系统的通用基石。
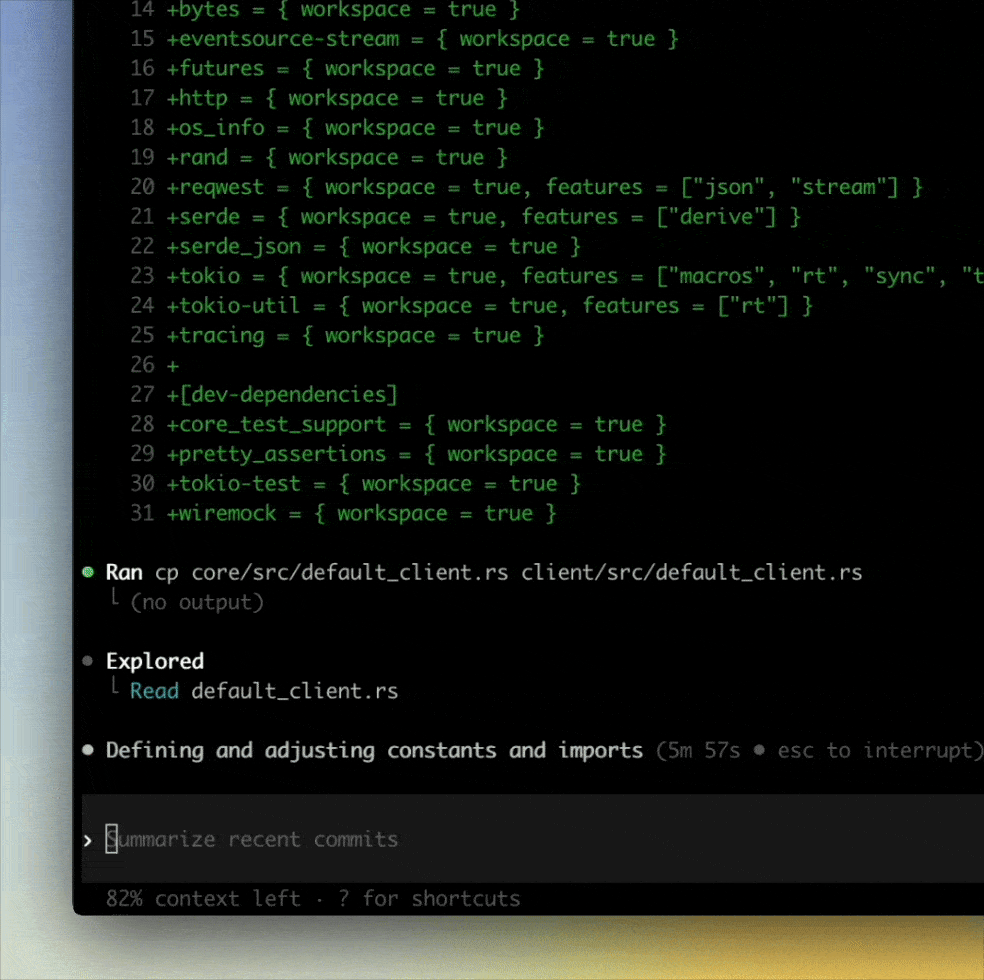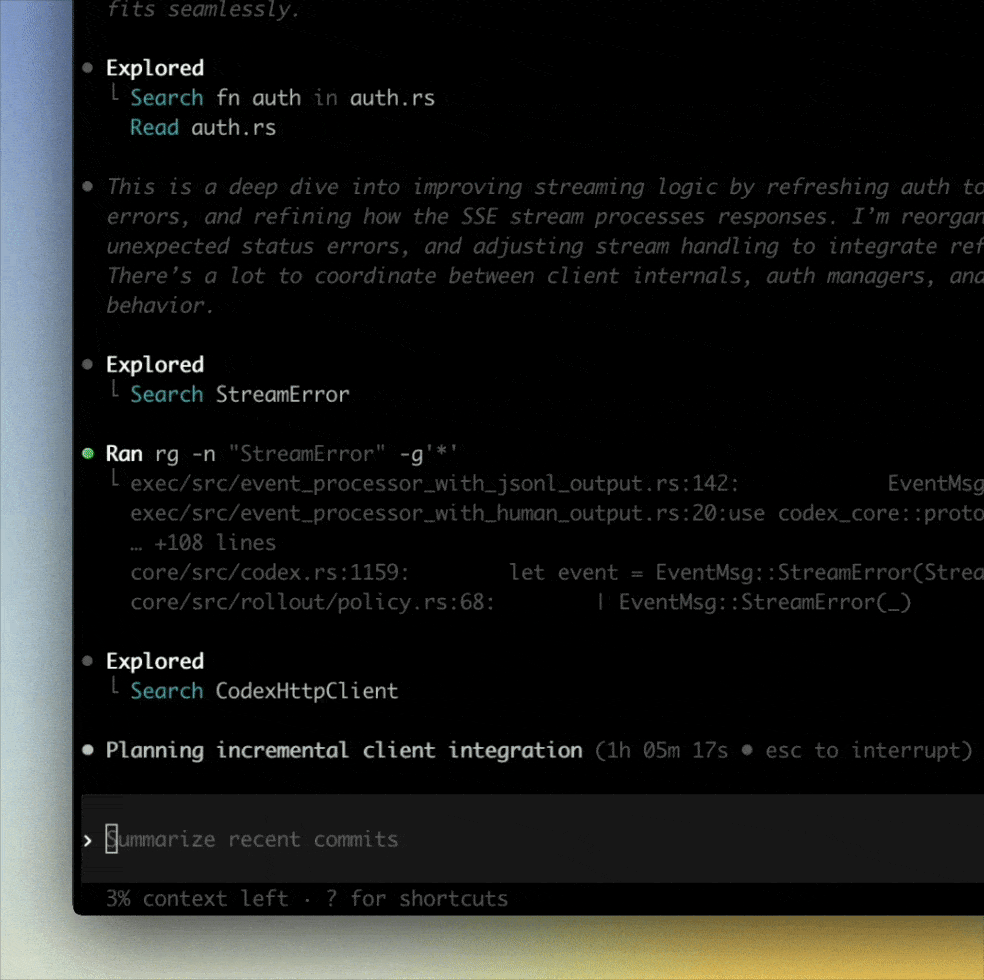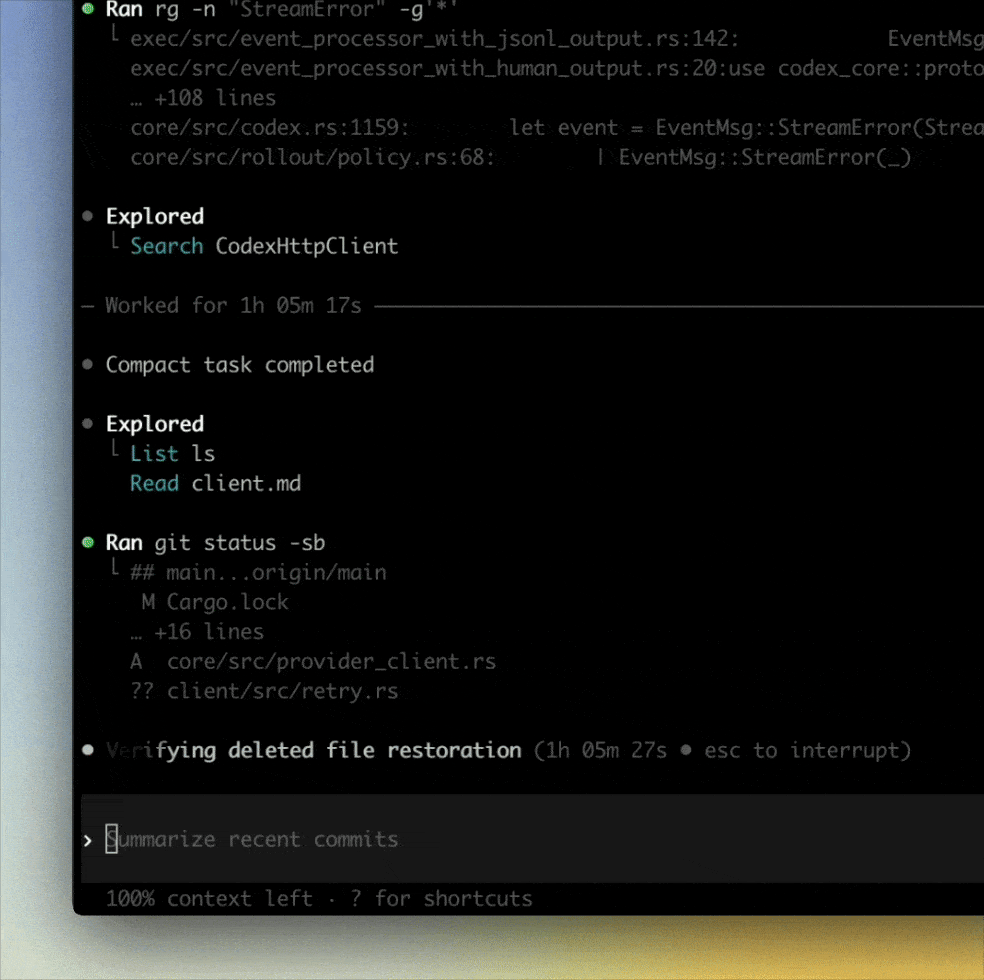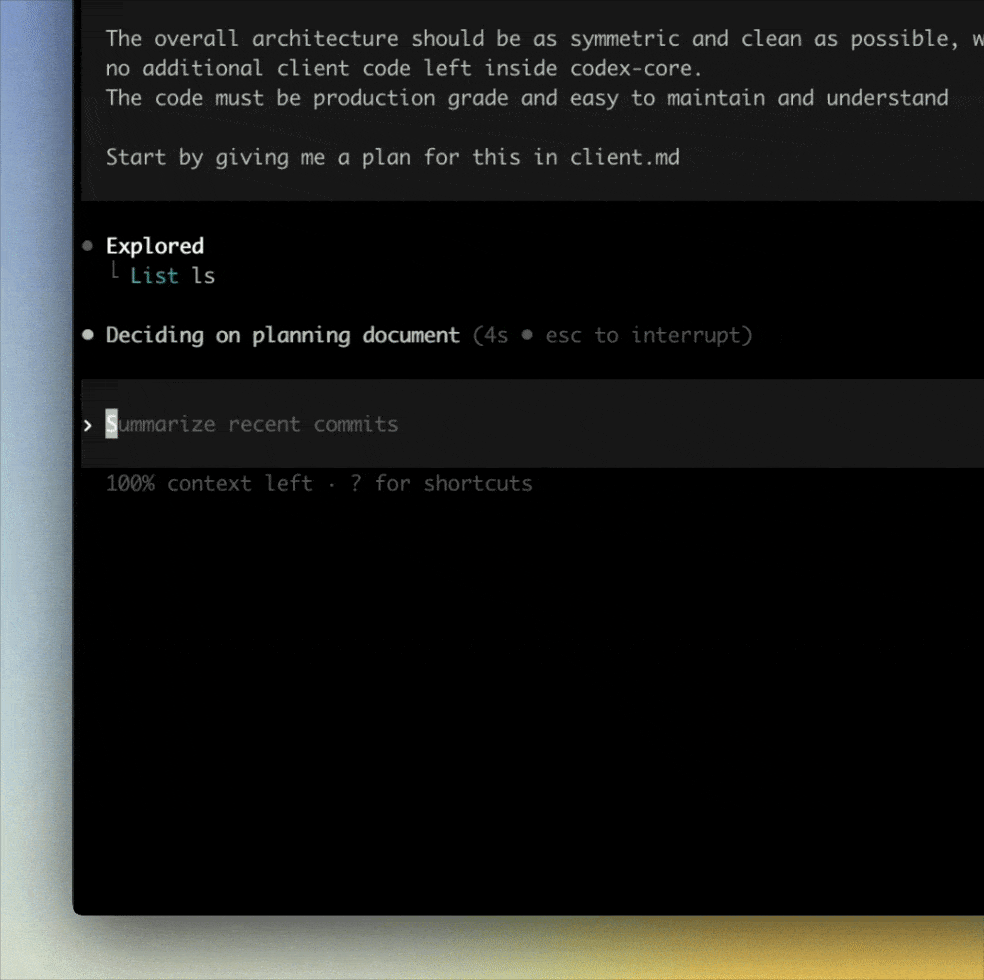
在METR评估中,GPT-5.1-Codex-Max长程任务能力,成为了新的SOTA。
在OpenAI内部,已有95%工程师每周都在用Codex,自从引入之后,团队的Pull Request数量提升约70%。
现在,GPT-5.1-Codex-Max搭配着持续升级的CLI、IDE 扩展、云集成与代码审查工具,编程效率直接起飞。
一些网友试用第一手感觉,瞬间惊艳了。


GPT-5.1 Pro上线,首测来了
至于GPT-5.1 Pro,正如开篇所说,OpenAI只是在版本更新日志里写了两段介绍。
虽然官方没有单开一篇博客,但提前拿到内测资格的大佬们,都非常兴奋地在第一时间放出了自己的体验感受。

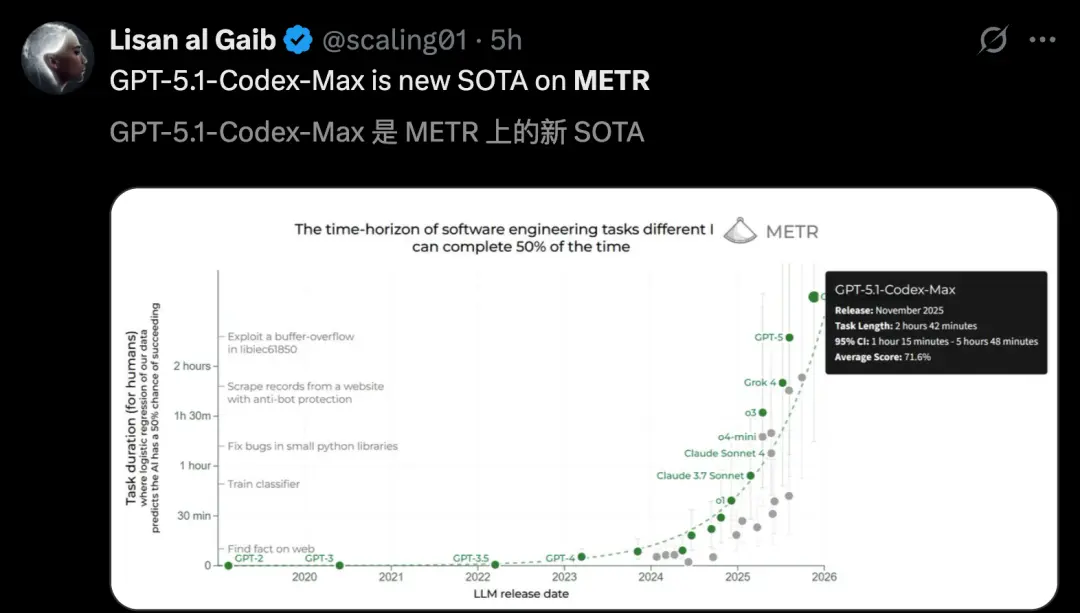
对于GPT-5.1迭代后的性能,Epoch AI三方评估后称,几乎与GPT-5实力相当。
它们在high(高)推理模式下,能力指数(ECI)得分均151。
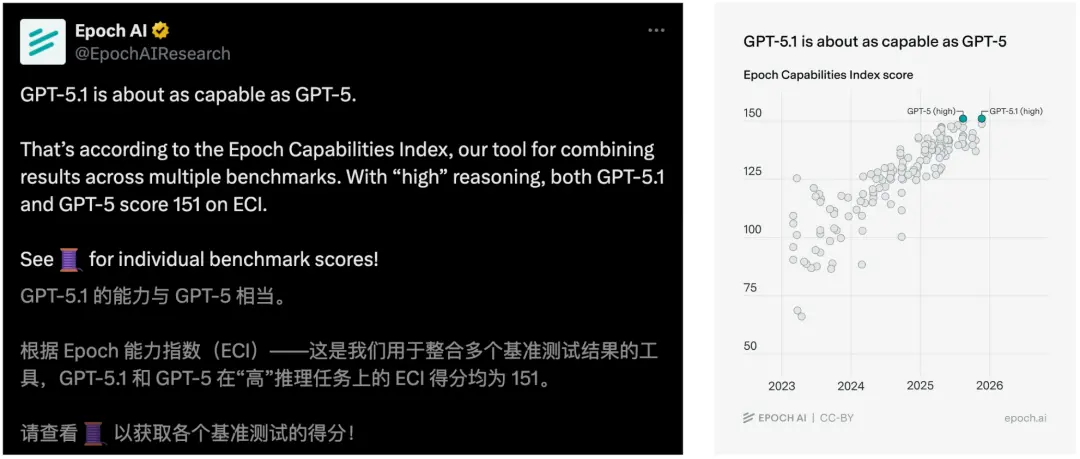
杰克森实验室教授、人类免疫学家Derya Unutmaz表示,性能相较之前明显提升了一个档次的GPT-5.0 Pro,是他现在最喜爱的模型。
在下面的例子中,他分别向5.0和5.1 Pro询问了免疫学领域最重要的未解之谜,并要求这两个模型深入浅出地剖析每个问题,以便让没有免疫学学位的人也能理解其重要性。
其中,前两个回复来自GPT-5.1 Pro,接下来的两个较短回复来自GPT-5.0。
可以看到,GPT-5.1 Pro明显更胜一筹,因为它能让没有免疫学背景的人更轻松地理解这些解释,并且清晰地阐明了这些问题的重要性和潜在价值。
对比而言,GPT-5.1 Pro在清晰度和洞察力方面都有质的提升。它的回答在保持深度的同时,内容更完整自洽、更形象生动、也更易于理解。
虽然GPT-5.0的回复在内容上也同样出色,但剖析得不够透彻。

GPT-5.1 Pro

GPT-5.0
HyperWrite AI的CEO Matt Shumer也在一篇超级长的体验报告中表示:GPT-5.1 Pro是目前最好的“大脑”,虽然很慢,但深思熟虑。
对于大多数日常工作,Gemini 3更好;毕竟在一个独立的界面中等待10分钟才能得到答案显然并不理想。
但对于任何需要深入思考、规划和研究的任务,以及任何必须一次性做对的事情,GPT-5.1 Pro更好。
长文地址:https://shumer.dev/gpt51proreview
反应较慢,但聪明得离谱
它不仅比大多数人类更擅长推理,而且在处理真正棘手的难题时,也比其他任何模型都要聪明。
预计几天内,就会出现它解决了一些人们认为当今AI系统力所不及的问题的例子。
指令遵循能力是最大的亮点
它真的会严格执行你的要求,而不会跑偏。
对于严肃的编码任务,它给人的感觉不那么像一个“助手”,而更像是一个依据规格说明书工作的外包工程师(哪怕你的规格说明书有点模糊)。
前端和用户体验设计,以及写作,都是弱项
不管是创意写作,还是设计漂亮的UI,Gemini 3都要更胜一筹。
但最大的弱点还是界面
它只能在ChatGPT中使用,无法集成到IDE里,也无法连接到其他工具链中。这一点与GPT-5 Pro如出一辙。