DeepSeek-V4预览版本,终于发布了。今日,DeepSeek官方宣布:拥有百万字超长上下文的deepseek-v4-pro和deepseek-v4-flash两款模型发布并开源,即日起登录官网或官方App即可与最新的DeepSeek-V4对话,探索1M(百万)超长上下文记忆的全新体验,API服务已同步更新。

文 丨《BUG》栏目 周文猛

据官方公布基准测评,在上下文长度、知识、推理及Agent等能力上,DeepSeek V4性能比肩国际顶级闭源模型,达到国际开源模型一流水平。《BUG》栏目对比发现,在API调用价格上,去年以一己之力撬动国内大模型行业降价的DeepSeek,V4版本再次开出了行业“最低价”。
“虽然每百万Tokens调用价格国内模型均未下降太多,但超长上下文长度及不俗的性能,让其极具竞争优势!”有业内人士在与《BUG》栏目沟通中感慨:“那个大模型价格屠夫,又回来了!”
性能比肩顶级闭源模型,知识、推理能力领先
根据DeepSeek的官方介绍,V4系列共包括两个版本模型:DeepSeek-V4-Pro总参数1.6T、激活参数49B,预训练数据33T;DeepSeek-V4-Flash总参数284B、激活参数13B,预训练数据32T;两者均原生支持100万token上下文。
据DeepSeek披露的基准测试数据,在知识与推理类测试中,DeepSeek-V4-Pro-Max在Apex Shortlist和Codeforces两项测试中取得了最优性能,超越Claude-Opus-4.6-Max、GPT-5.4-xHigh、Gemin-3.1-Pro-Hight等国际模型,展现了极强的逻辑与算法能力;在SimpleQA Verified测试中较Gemini-3.1-Pro-High略有差距但领先于Claude和GPT。
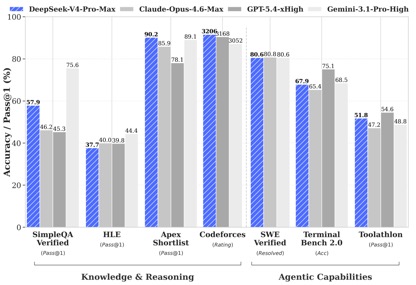
在Agentic能力测评中,V4、Opus-4.6、Gemin-3.1-pro三款模型在SWE Verified任务上打成平手,且DeepSeek在Toolathlon任务上取得了仅次于GPT-5.4-xHigh的水平,在Terminal Bench 2.0上取得了优于Opus-4.6的水平,体现了在复杂指令执行与工具调用场景下的优势。
目前DeepSeek-V4已成为公司内部员工使用的Agentic Coding模型,根据评测反馈使用体验优于Sonnet 4.5,交付质量接近Opus 4.6 非思考模式。
在数学、STEM、竞赛型代码的测评中,DeepSeek-V4-Pro 超越当前已公开评测的绝大多数开源模型,取得了比肩世界顶级闭源模型的成绩。
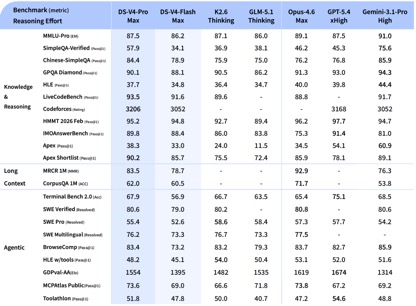
综合来看,在知识处理及推理能力上,DeepSeek-v4取得了较国内开源模型全方位领先,比肩国际的测评能力。但在Agentic能力方面,虽然最新的DeepSeek-v4有了不错的提升,但较国内及国际第一梯队的能力并未拉开差距,彼此各有领先。
“标配”100万上下文,价格屠夫“回来了”
相比于各项基准测试中体现的性能优势,本次V4发布最大的特色,莫过于长文本能力的突破以及API调用价格的进一步下探。
得益于DeepSeek-V4开创的全新注意力机制,V4通过在token维度进行压缩并结合DSA稀疏注意力(DeepSeek Sparse Attention),实现了全球领先的长上下文能力,且相比传统方法大幅降低了对计算和显存的需求,将1M(一百万)上下文变成了DeepSeek所有官方服务的标配。
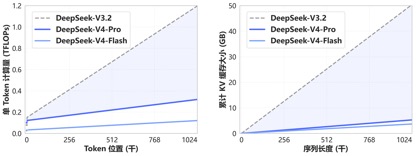
一年前,100万上下文还是Gemini的独家王牌,即使是近期发布的多数主流国产开源模型中,模型上下文的长度也多位于128K—200K区间,而DeepSeek直接把百万上下文从“高端闭源功能”,做成了开源标配。
在API价格调用上,相较于目前GLM-5.1输入单价1.3元-2元/百万Tokens(缓存命中),以及Kimi-K2.6 1.1元/百万tokens(缓存命中),DeepSeek-v4 -pro及flash两个版本,输入单价分别为1元/百万tokens及0.2元/百万tokens,虽然价格降幅不大但均为最低,且上下文长度扩展了数倍。
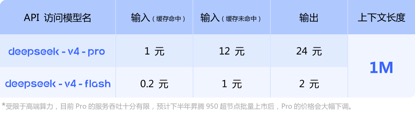
(DeepSeek-v4系列模型API调用价格)
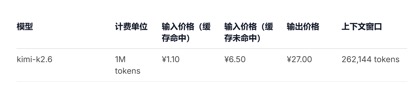
(Kimi-k2.6模型API调用价格)
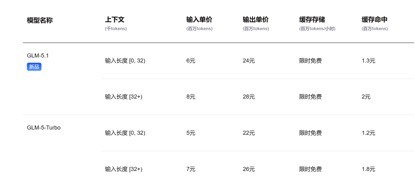
(GLM-5.1模型API调用价格)
“DeepSeek-v4此次发布带来的性能突破,较DeepSeek-R1发布时带给外界的冲击要小了一些,各项性能依然处于第一梯队,但领先优势并未完全拉开。”在业内人士看来,“此次V4模型的发布,更多的在于长文本能力的提升及价格的进一步下探。”
该人士感慨道:“此前DeepSeek-V3及R1模型发布后,其通过底层技术创新带来的性能优势,直接推动整个国内大模型行业集体降价,虽然此次V4版本每百万Tokens调用价格较国内同行并未下降太多,但依然具有竞争力,那个大模型价格屠夫又回来了!”。
“下半年批量上华为算力,Pro价格会大幅下调”
值得注意的是,在DeepSeek-v4公布API价格的信息的最下层位置,官方特别标注指出:“受限于高端算力,目前Pro的服务吞吐量十分有限,预计下半年昇腾950超节点批量上市后,Pro的价格会大幅下调。”

这意味着,此次发布的v4系列模型,已经针对华为昇腾950超节点完成适配,只要昇腾950上市,广大用户便可基于国产算力用上比肩国际顶级闭源模型的DeepSeek-v4。
在官方开源的技术文档中,DeepSeek也提及了这一点,直言v4已在NVIDIA GPU和HUAWEI Ascend NPUs平台上验证了精细粒度的EP(专家并行)方案,相较于强大的非融合基线,其在通用推理任务上可实现1.50-1.73倍的加速效果,而在对时延敏感的场景(如RL推演和高速代理服务)中则可达到1.96倍的加速效果。

而在V4发布后,华为昇腾也同步宣布“超节点全系列产品支持DeepSeek V4系列模型”。据悉,昇腾950通过融合kernel和多流并行技术降低Attention计算和访存开销,大幅提升推理性能,结合多种量化算法,实现了高吞吐、低时延的DeepSeek V4模型推理部署。
本月上旬,英伟达创始人黄仁勋在接受Dwarkesh Patel专访时曾言:“如果DeepSeek先在华为平台上发布,那对我们国家(美国)来说将是灾难性的。”在黄仁勋看来,虽然DeepSeek是一款开源模型,同样可被用于英伟达产品上,但如果DeepSeek专门针对华为算力进行优化,在高端算力采购受限等局限下,英伟达将处于劣势。
如今看来,虽然DeepSeek也针对英伟达算力进行了EP方案验证,但黄仁勋担心的事情还是发生了。在业内人士看来,“V4是算力博弈逼出来的产物,在未来一年,国产大模型跑在国产卡上,将逐渐成熟。”
多模态能力仍未出现
比较遗憾的是,DeepSeek V4虽然发布了,但该版本依然是一款纯文本模型,没有太多的文生图、文生视频等多模态能力。这也让普通用户快速体验评测一款模型,平添了不少难度。

毕竟,在大语言模型能力不断提升、幻觉率逐渐下降的当下,常规、单一的知识问答,已很难客观反映一款模型的综合能力。对于多数用户而言,想要直观感受V4模型的能力,还得下载并亲自用上一阵子。
V4系列模型发布的同时,近期DeepSeek还曝出了计划融资500亿元的消息,有接近DeepSeek的知情人士透露,DeepSeek融前估值为3000亿元,约合440亿美元,目前腾讯控股、阿里巴巴集团均正在洽谈投资DeepSeek。不过,对于融资相关事宜,DeepSeek方面至今未正面回应媒体问询。
或许,对于DeepSeek创始人梁文锋而言,在全球大模型“智力”增长放缓,行业人才竞争加剧、行业多模态化、Agentic化趋势不断凸显的情况下,借V4发布适时融资壮大实力,也不失为一个明智之举。