两年时间,Google从被OpenAI按在地上摩擦,到用Gemini 3.0 Pro把“落后”两个字彻底撕碎,狠狠甩了奥特曼一脸。AI江湖的王座,Google终于还是坐实了!最近Google的Nano Banana Pro和Gemini 3,大家都玩嗨了吧~就连奥特曼都在全员信中承认,Google已经“反超”。可以说,年底这波大招,成功地“让Google再次伟大”!尤其是Nano Banana Pro展现了生成式AI技术的重大突破。

网友用Nano Banana Pro制作的梗图
所有人都赞不绝口,很多大佬都成了自来水,比如Shopify的CEO直夸Nano Banana Pro简直疯狂!

Google这把王座,基本是坐稳了。
回看这个11月,全球科技格局经历了一场剧烈的板块漂移,准确地说,是在Google和OpenAI之间。
两家产品都是密集发布,GPT-5.1、Gemini 3,你方唱罢我登场。
在经历了长达三年的被动防御战,Google以一种近乎挑衅的自信姿态重回人工智能霸主的地位!
上个月,作为对手的奥特曼告诉OpenAI的同事们:
Google最近在AI方面的进展可能会“给我们公司带来一些暂时的经济阻力”。

所以,Google的Gemini 3和Nano Banana Pro为何能够突然断层一样领先?
是因为自研TPU带来的算力扩充,还是Google掌握了全新的AI技术?或许都有,但在社区的讨论中,一种最可能的底层原因开始浮出水面。
Google的创始人放弃在私人小岛度假,并且重回AI第一线,重启“创始人模式”。

谢尔盖效应:创始人模式拯救Google,并带来Gemini 3.0
身价千亿创始人
亲自下场修配置
如果说劈柴是GoogleAI转型的执行者,那么联合创始人谢尔盖·布林(Sergey Brin)的回归则是这场变革的精神图腾。
据外媒报道,布林早已重返Google山景城总部。

他并没有选择坐在高管套房里,而是直接入驻了被称为“Building 43”的工程中心。
X的网友将布林的回归定义为:Google在一年内从“远远落后”到“轻松称霸”。
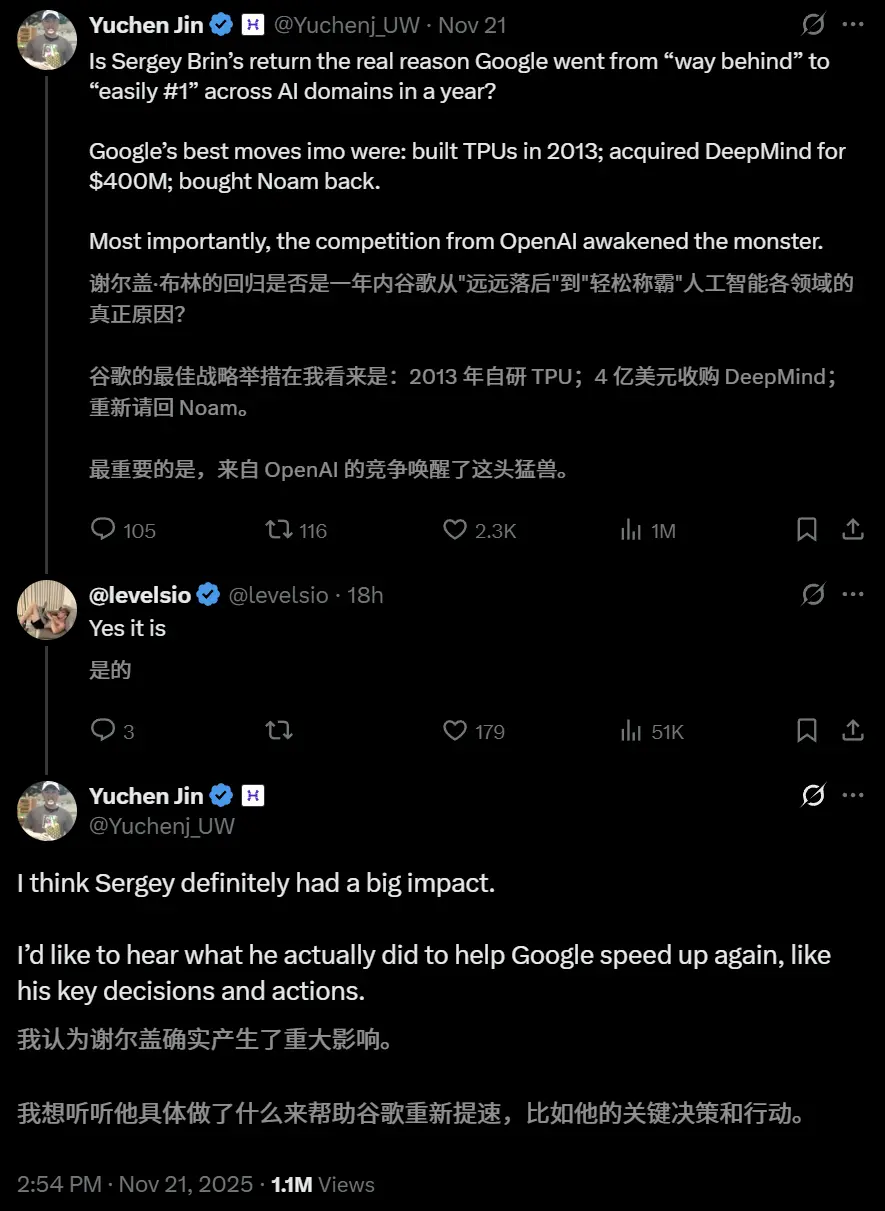
这个观点引发了社区广泛的讨论!
网友迅速从嗨到不行的状态立马上升到哲学层面:Google怎么一下子能做出两个这么厉害的产品?
一个观点是,Google在技术上从未落后,但是Google得了一个病:“大公司病”。
OpenAI作为创业公司,加上奥特曼的激进战略,OpenAI一直敢于发布产品,即使市场认为这个产品并不完美。
而布林的回归和影响力,正是打破了Google的这种僵局。
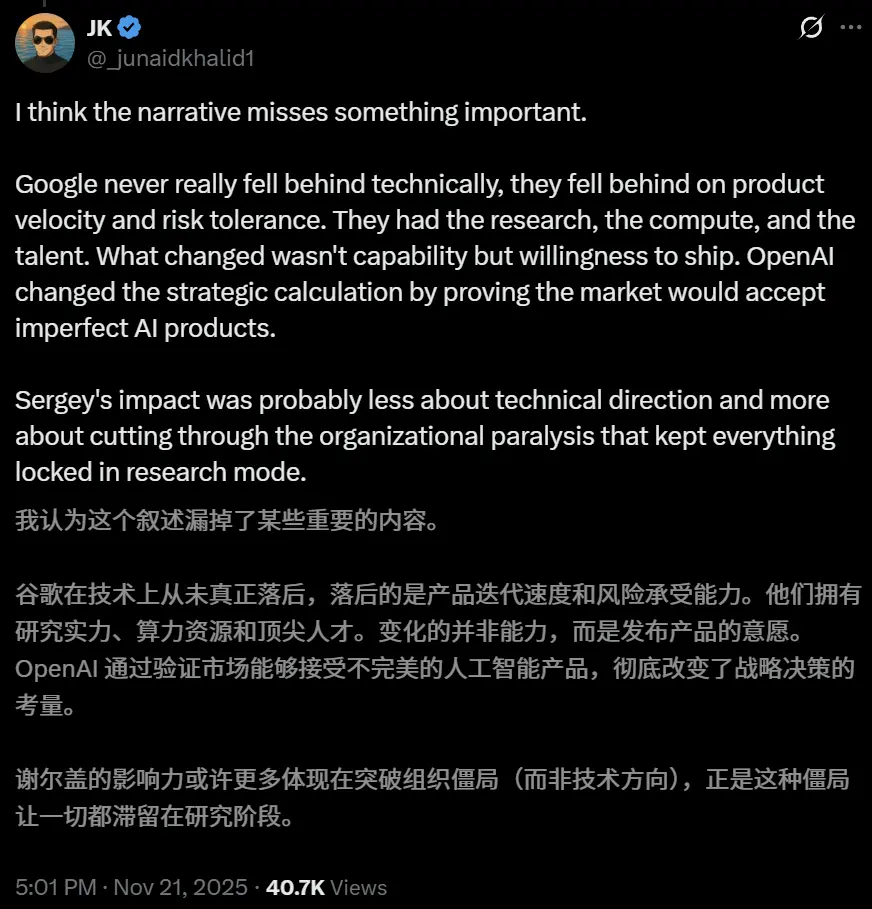
这充分展示了强大领导力的重要性。
甚至有网友认为,如果不是创始人打通了Google部门之间的壁垒,Gemini 3或者Nano Banana Pro并不会以“全面出击”的方式上线。
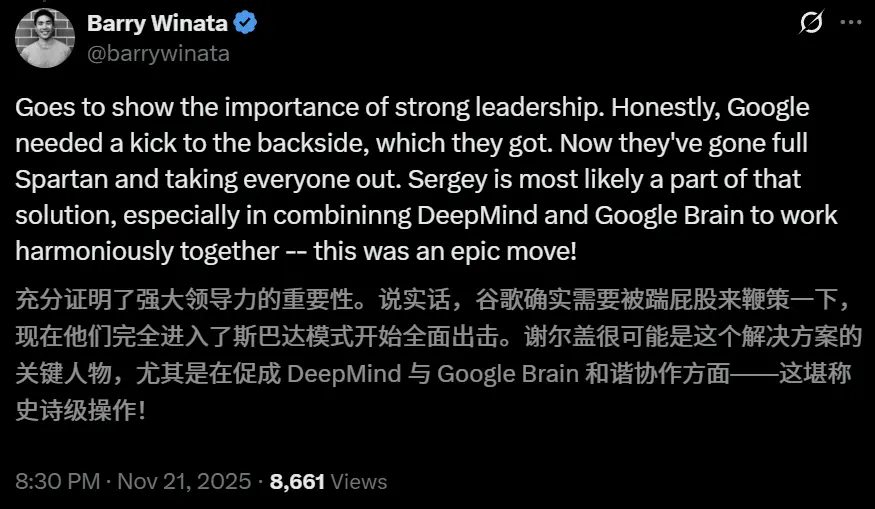
作为Google的创始人和图腾人物,谢尔盖放弃退休后在私人小岛享受生活。
而是脚踏实地的重返硅谷,拯救Google。
布林的回归不是为了发表愿景演讲,而是为了写代码。
据说,他回到Google后提交了多年来的第一个CL(Changelist,Google内部的代码修改请求),这一行为在工程师内部产生了地震般的效应:
如果身价千亿的创始人都在修补配置文件,那么任何产品经理都没有理由以“流程”为借口阻碍发布。
布林的存在直接催化了Gemini 3项目的加速,他专注于解决模型在长逻辑链推理上的“长尾问题”,这是之前职业经理人们因追求短期指标而忽视的领域。
很多网友表达了类似的看法。
Google太强,也太大,它得了大公司病,到处是繁文缛节。
但布林的回归,让Google再次成为一家AI时代的“创业公司”。
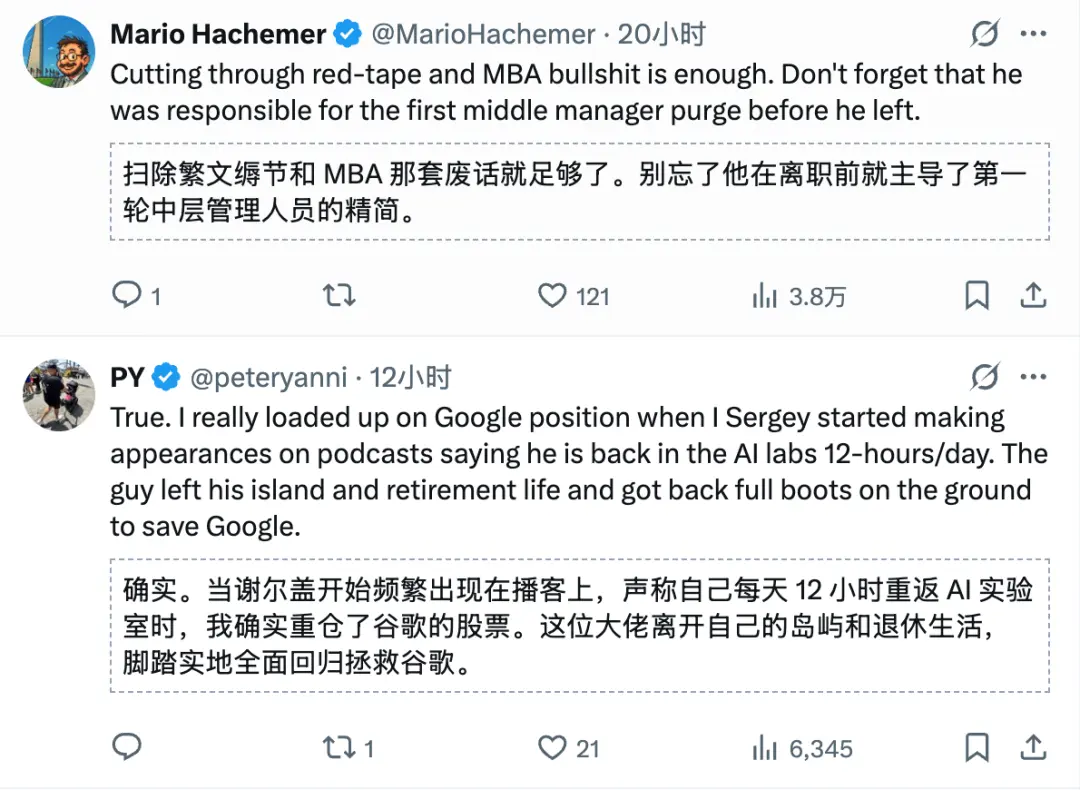
创始人的回归,不仅重塑了文化。
有网友说,Google将所有人工智能相关工作整合到哈萨比斯旗下的DeepMind也是至关重要的一步棋。
这里就有人问了,创始人虽然具有图腾般的象征和号召力,但是他有实权吗?
最有名的独立开发者levelsio给出了答案:
谢尔盖·布林与拉里·佩奇仍共同持有Alphabet的股份。
更重要的是,他们共同持有87.4%的B类投票股,这赋予了他们51.4%的总投票权
想象一下,当Google的官僚体系(他们确实存在不少)试图阻碍你时,有谢尔盖站在你这边——只需给他发条消息,就能获得通行许可。
这相当于获得了一张创新的通行证:你可以自由创造任何产品、发布任何功能、推出任何项目,几乎不受限制。
这让Google重新像一家小型初创公司那样运作,我认为这正是他们再次取胜的原因。

虽然这波Google有望重夺王座,但是在此前面对OpenAI时,Google一度掉以轻心。
拉响红色警报
AI部门紧急重组
起初,ChatGPT刚出来时,Google并没有放在眼里——
这不就是我们自己玩过的LaMDA吗?
那个内部跑过、甚至把一个工程师忽悠到以为它有意识、但死活没敢放出来的生成式AI聊天机器人。
谁也没想到,ChatGPT眨眼间就成了史上增长最快的消费级产品,甚至还能替代搜索引擎拿来查资料、做研究。
这时Google才反应过来:坏了,真要出大事了。
虽然没人正式喊,但公司里实质上已经“code red”了。

于是,Google赶紧把自家两个最强的AI实验室缝在了一起——GoogleDeepMind由此诞生。
从追赶到碾压,Google王者归来
这次合并把DeepMind在强化学习、神经科学启发AI上的深厚积累,和GoogleBrain在大规模机器学习系统上的优势完美结合,直接加速了顶级模型的研发。
Gemini正是合并之后,第一个落地的大项目。
它从设计之初,便坚定地走上了原生多模态路线,而不是在单模态模型上后期缝补,从而彻底避开了GPT-4等竞品的后天短板。
同时,也完全由Google自研的TPU进行训练。
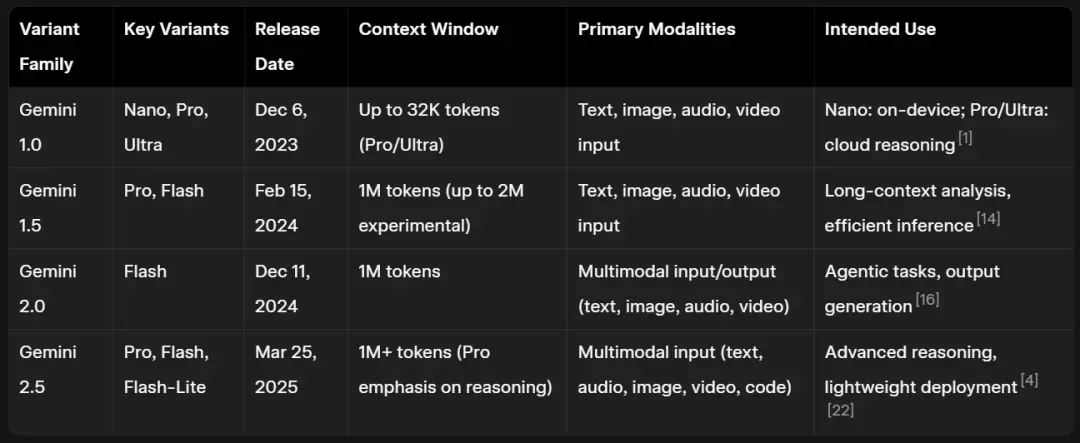
2023年12月6日,第一代Gemini正式发布。
Gemini 1.0共有三大版本:Gemini Ultra、Gemini Pro、Gemini Nano,其中Pro和Ultra支持最长32k token上下文。
作为当时Google最强大的模型,Gemini Ultra在MMLU拿下90.0%,数学(MATH 53.4%)和视觉问答等多项榜单碾压GPT-4。

2024年2月15日,Gemini 1.5发布。
上下文窗口直接拉到100万token(Pro),性能追平甚至超Gemini 1.0 Ultra,但算力需求更低。同时,新增Gemini 1.5 Pro和Gemini 1.5 Flash。
2024年6月,Google再次将Pro的上下文窗口,提到了惊人的200万token。
2024年9月24日,Gemini 1.5 Pro-002和Flash-002上线,更成熟、更便宜。

2024年12月11日,Gemini 2.0亮相,主打“agentic”能力,原生支持实时音视频流,新推出Multimodal Live API。
2025年2月,Google带来了更快Flash-Lite和Pro Experimental,并且还新增了Thinking Mode——推理过程完全可见。
2025年3月25日,Gemini 2.5以Pro Experimental首秀。
Google称,这是迄今最聪明的模型,内置超强推理、编程、多模态复杂任务能力无敌。
2025年6月17日,2.5 Pro与Flash全面开放,支持企业级高吞吐。
2025年10月7日,Gemini 2.5 Computer Use上线,专攻浏览器操控,在手机UI控制上也极具潜力,把整条产品线的智能体能力又拉高一个台阶。
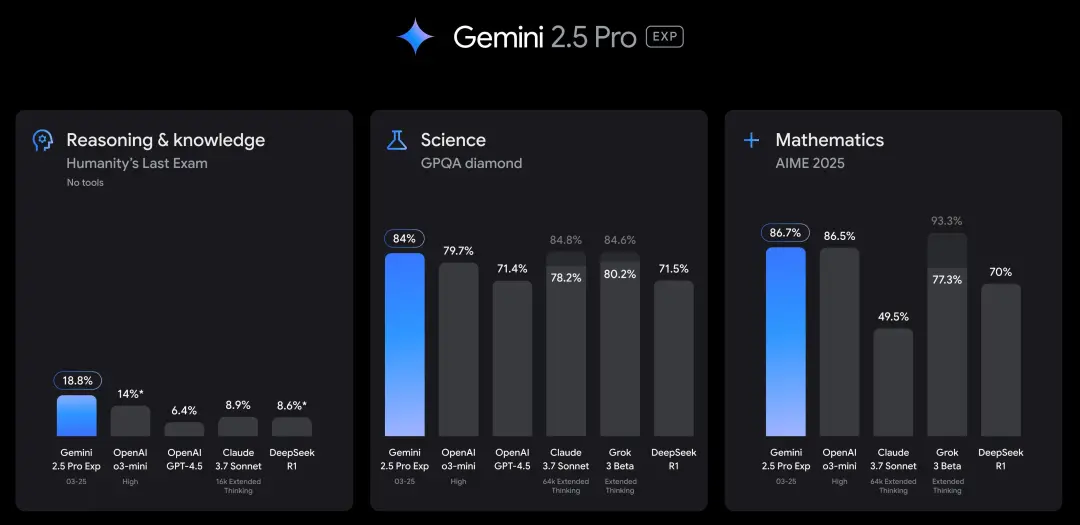
2025年11月18日,全新亮相的Gemini 3.0 Pro和Gemini 3.0 Deep Think,直接成了2025年11月最猛的现役模型。
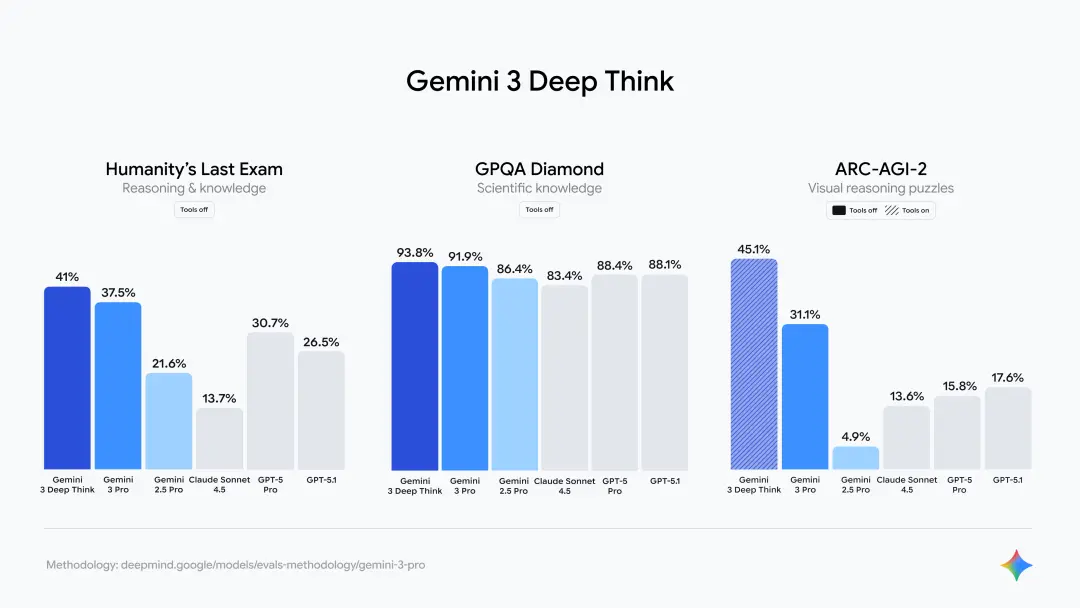
一上线,Gemini 3.0 Pro就在20个基准测试里狂砍19胜,把一众大模型按在地上摩擦。
尤其是在Humanity's Last Exam上,它凭借着41%的准确率把OpenAI的GPT-5 Pro(31.64%)打得满地找牙。
模型核心设计原则
正如前面提到的,Gemini全系列从零开始联合训练,原生多模态,训练数据直接覆盖文本、图像、音频、视频,能轻松处理各种模态混排输入输出。
这种天生多模态设计彻底甩开后期改造的老路子,自然涌现出了跨模态推理能力,比如边看视频边回答文本问题。
架构采用仅解码器Transformer,加入多查询注意力等优化,优先保证泛化能力而非堆砌专用编码器。
效率方面,第一代采用分层设计(Ultra极致能力、Pro平衡、Nano/Flash低延迟设备端)+ 混合专家(MoE)稀疏激活,只点亮当前输入需要的子网络,训练推理都省算力。
Gemini 1.5及2.5则进一步用稀疏MoE Transformer,把上下文窗口标配做到100万token,几小时视频也能轻松吃下。
CEO也有功劳?
除了创始人回归,Google本身内部的快速迭代。
很多人也忽略现在CEO 劈柴的能力。
正如很多人在3年前将Google的落后归咎于劈柴,却不敢承认,正是劈柴让Google重回正轨,并完成对OpenAI的超越。

劈柴在2015年接任CEO时,被视为硅谷最完美的职业经理人:温和、外交手腕高超、善于达成共识。
在移动互联网的红利期,这些特质确保了Google这艘巨轮的平稳航行。
然而,当2022年AI军备竞赛爆发,这种“和平时期”的领导风格迅速成为众矢之的。
但今天外媒BI的一篇文章,深入分析了劈柴在Google这波逆袭中扮演的重要角色。

像Gemini 3这样强大的产品需要多年时间、大量技术研究和底层架构才能实现。
Google在这方面已深耕许久,正是因为劈柴推动公司转向“AI优先”理念也已近十年。
如今这些努力终于结出硕果。

背景故事:
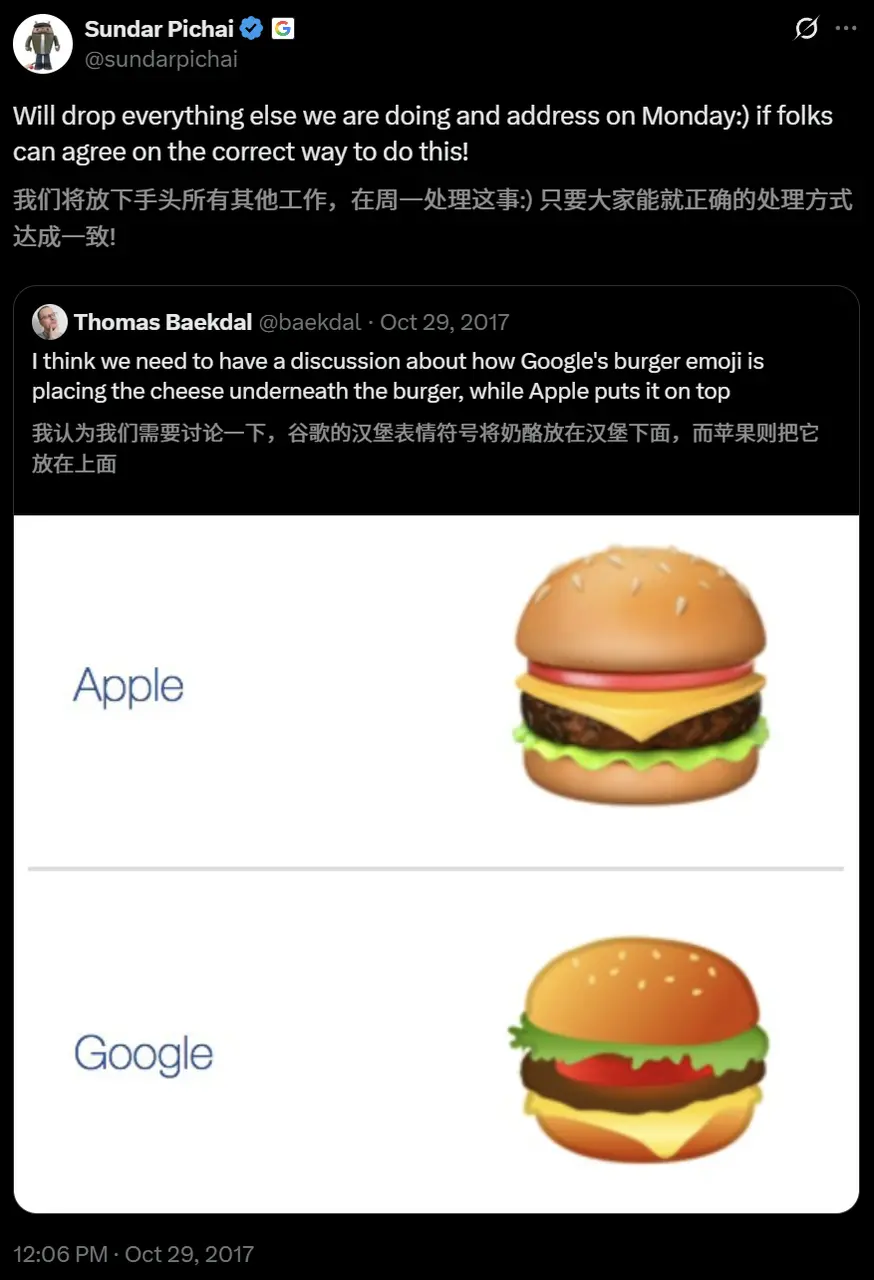
2017年,Google的汉堡emoji把奶酪放在肉饼下面,瞬间全网炸锅。这直接引发了一场又好笑又撕裂的互联网大战,大家疯狂争论“正确”的汉堡该怎么叠。
皮查伊当时发推调侃:你们要是能统一意见,我就放下手头一切马上修。结果大家真的统一了,Android没几天就更新,把奶酪挪到了肉饼上面。
现在看来,Gemini 3.0也完美遵守了这个“正确顺序”。
算力不够用
容量必须每6个月翻一番
Google这波成功,除了在战略和文化上,被“创始人模式”带飞了一波。
但千万不要忽略最根本的原因,Google的算力!

即使布林给所有Google工程师都打了“鸡血”,没有算力一切都白搭。
这就要归功于Google的TPU了。
本月早些时候的全体员工大会上,GoogleAI基础设施负责人Amin Vahdat直接说:公司必须每六个月就把服务容量翻一倍,才能满足人工智能服务的需求。

据CNBC报道,这位GoogleCloud副总裁还放了幻灯片,上面写着未来4-5年要实现“1000倍”扩展。
支撑这1000倍增长的核心,是Google在2025年发布的第七代张量处理单元(TPU),代号“Ironwood”。

这款芯片不仅是硬件的迭代,更是Google垂直整合战略的巅峰之作。
千倍扩展的难题
目前AI最大的瓶颈就是英伟达GPU产能跟不上。
几天前英伟达财报电话会上还说AI芯片“卖到断货”,数据中心收入单季暴增100亿美元。
芯片和其他基础设施限制直接影响Google新AI功能上线。
11月6日的全体大会上,劈柴举了上个月刚升级的视频生成工具Veo的例子:
“Veo刚出来的时候多令人兴奋啊,如果能在Gemini App里放开给更多人用,用户量肯定爆,但我们就是给不了——算力根本不够。”
虽然哪家AI公司都缺算力,但是相比OpenAI,GoogleTPU正是他们制胜的法宝。
Google的“1000倍”算力扩张揭示了一个残酷的现实:AI行业正在经历剧烈的阶级分化。
地主阶级: 拥有吉瓦级数据中心和自研芯片的巨头,比如Google。他们制定规则,出租算力,收取租金。
佃农阶级: 依赖巨头基础设施构建应用的初创公司。无论他们的模型多优秀,最终的利润大头都将流向基础设施提供商。
因此,这也是为何OpenAI也想要做芯片的根本原因。

从年初的Gemini 2.5到年底的Gemini 3,如果单从版本号来看,Google的行动可以说缓慢至极。
关于GPT-5和Gemini 2.5谁更好用的话题也是经久不衰。
但是随着Gemini 3、Nano Banana Pro的出世,所有人都突然回过神来,Google还是那个Google,Google还是SOTA!
这里面既有创始人放弃私人小岛重回一线的魄力,也有GoogleTPU多年来的厚积薄发。
作为AI领域唯一一家技术全栈的科技公司,让我们期待一下2026年,Gemini 4甚至Gemini 5能否让我们看到AGI的曙光。
