GPT-5.1-Codex-Max号称最先进的智能体编码模型,周四面向付费ChatGPT用户推出。据OpenAI,新模型的SWE-Bench Pro测试准确率56.4%,高于GPT-5.2的55.6%,评估发现其网络安全方面的能力大幅提升,虽然尚未达到“高”级别,但公司为跨越此门槛做准备。
Altman称,模型对网络安全将产生净收益,我们正处于“真实影响阶段”,正开始探索用于防御性网安工作的可信访问计划。OpenAI在进行邀请专业人员的可信访问计划试点。
在发布GPT-5.2系列模型一周后,OpenAI再次出手,美东时间18日周四推出基于GPT-5.2的新一代Codex模型GPT-5.2-Codex,号称最先进的智能体编码模型,聚焦专业软件工程和防御性网络安全,进一步巩固其在AI编程领域对GoogleGemini的竞争优势。
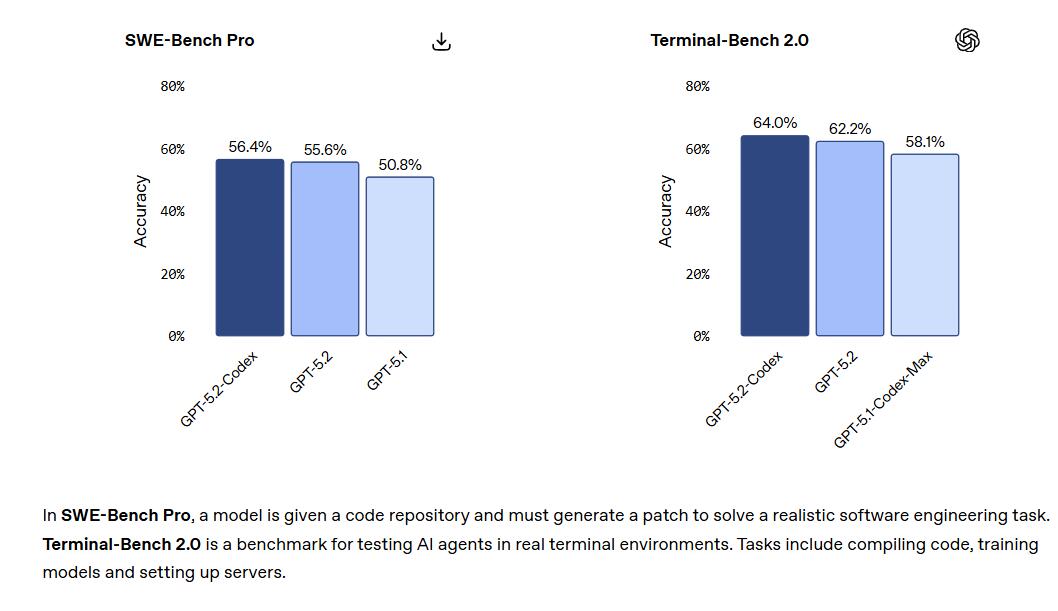
OpenAI介绍,GPT-5.2-Codex在编码性能、网络安全能力和长周期任务处理上均实现突破。GPT-5.2-Codex在SWE-Bench Pro测试中准确率达到56.4%,在Terminal-Bench 2.0测试中达到64.0%,刷新两项基准测试纪录。该模型已于发布当天在所有Codex界面向付费ChatGPT用户开放,API用户接入正在推进中。
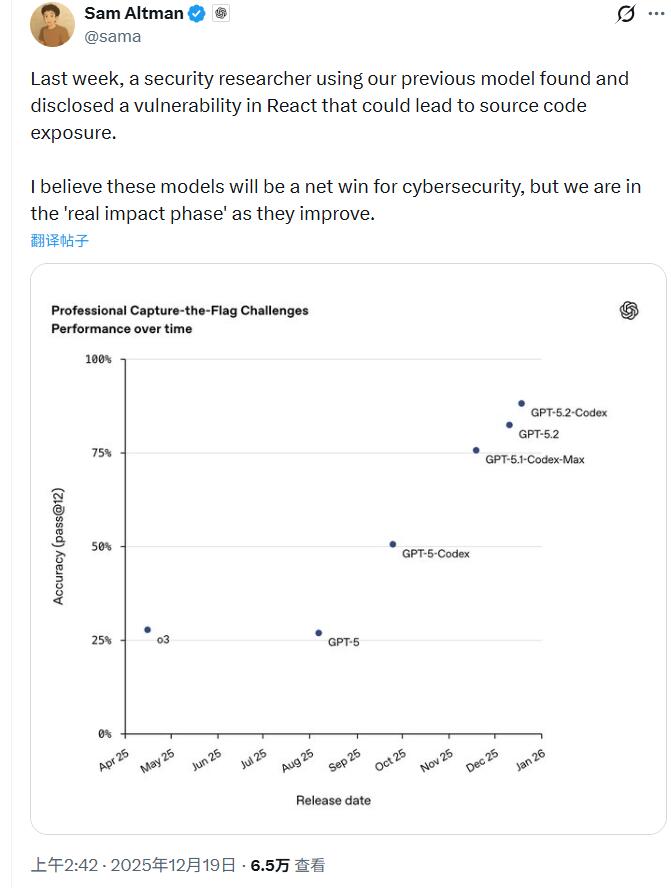
OpenAI特别强调GPT-5.2-Codex在网络安全方面的显著提升。CEO Sam Altman提到,本月早些时候,一名安全研究人员使用上一代模型GPT-5.1-Codex-Max就发现并负责任地披露了React中可能导致源代码暴露的漏洞。OpenAI方面认为,新模型尚未达到“高”级别网络安全能力,但公司正在为未来模型跨越这一门槛做准备。
OpenAI表示,GPT-5.2-Codex周四当天在所有Codex界面向付费ChatGPT用户发布,正在努力在未来几周内安全地为API用户启用访问。该司计划通过逐步推出、部署与保护措施相结合以及与安全社区密切合作的方式,在最大化防御影响的同时降低滥用风险。
本周四的发布延续了OpenAI在AI编程领域的进攻态势。
上周发布GPT-5.2时,OpenAI就援引编码初创公司的用户体验称,该模型拥有“最先进的智能体编码性能”,还披露GPT-5.2的Thinking版本在SWE编码能力测试中创下历史最高分,成为OpenAI首个性能达到或超过人类专家水平的模型。此举被视为对GoogleGemini 3在编码和推理能力上获得好评的直接回应。
编码性能再升级,针对大规模实战场景优化
GPT-5.2-Codex是GPT-5.2的优化版本,专门针对Codex中的智能体编码进行了强化。OpenAI表示,新模型在三个关键领域实现改进:通过上下文压缩提升长周期工作能力,在重构和迁移等项目级任务上表现更强,以及在Windows环境中性能改善。
在基准测试中,GPT-5.2-Codex在SWE-Bench Pro测试中准确率达到56.4%,高于GPT-5.2的55.6%和GPT-5.1的50.8%。在Terminal-Bench 2.0测试中,GPT-5.2-Codex准确率为64.0%,GPT-5.2为62.2%,GPT-5.1为58.1%。SWE-Bench Pro要求模型在给定代码库中生成补丁以解决实际软件工程任务,Terminal-Bench 2.0则测试AI智能体在真实终端环境中完成编译代码、训练模型和设置服务器等任务的能力。
GPT-5.2-Codex在长上下文理解、可靠的工具调用、改进的真实性和原生压缩方面均有提升,使其成为长时间编码任务中更可靠的合作伙伴,同时在推理过程中保持token效率。更强的视觉性能使GPT-5.2-Codex能够更准确地解读屏幕截图、技术图表和用户界面,可以将设计稿快速转化为功能原型。
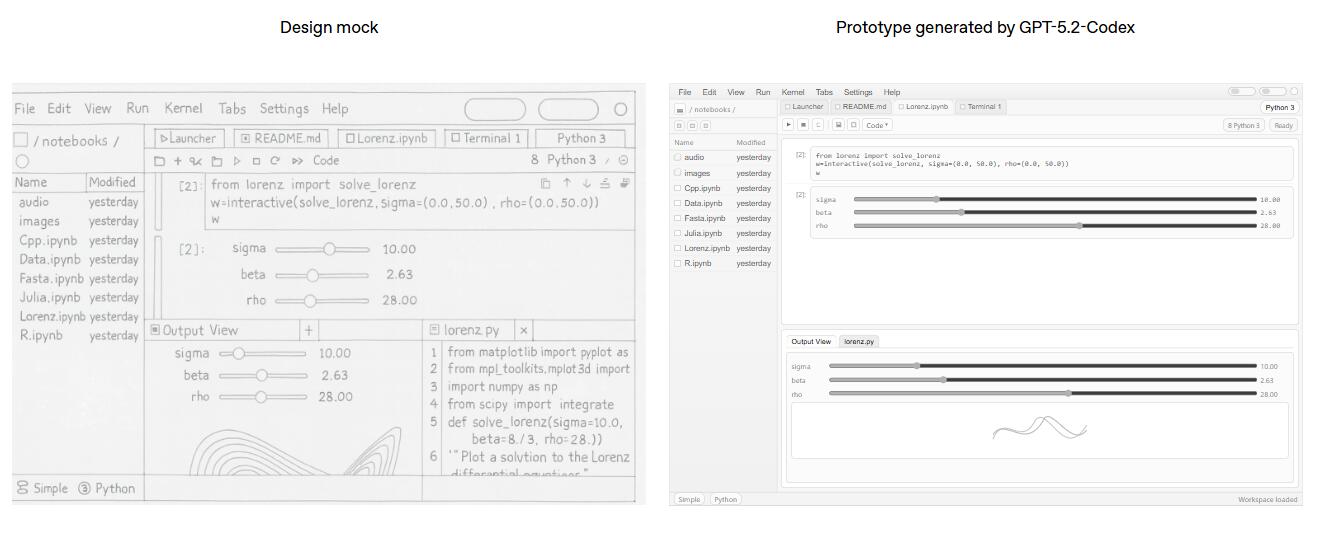
OpenAI表示,凭借这些改进,Codex能够在大型代码库中进行长时间工作,保持完整上下文,更可靠地完成大规模重构、代码迁移和功能构建等复杂任务,即使计划改变或尝试失败也不会失去追踪。
网络安全能力大幅跃升,为跨越“高”级别门槛做准备
网络安全成为GPT-5.2-Codex的另一个重点突破领域。OpenAI在核心网络安全评估中观察到,从GPT-5-Codex开始能力出现急剧跳跃,GPT-5.1-Codex-Max又实现一次大幅提升,如今GPT-5.2-Codex完成第三次跳跃。
在专业夺旗赛评估中,GPT-5.2-Codex展现出解决需要专业级网络安全技能的高级多步骤真实挑战的能力。据OpenAI的准备框架评估,GPT-5.2-Codex虽然尚未达到“高”级别网络安全能力,但该公司预计未来AI模型将继续沿着这一轨迹发展,正在按照每个新模型都可能达到“高”级别的标准进行规划和评估。
一个真实案例凸显了新模型的防御性网络安全潜力。12月11日,React团队公布了三个影响使用React服务器组件构建的应用程序的安全漏洞。Stripe旗下Privy公司首席安全工程师Andrew MacPherson在使用GPT-5.1-Codex-Max与Codex CLI研究另一个名为React2Shell的严重漏洞时,通过引导Codex执行标准防御性安全工作流程,意外发现了这些此前未知的漏洞并负责任地向React团队披露。
Altman在社交平台上披露:“上周,一名使用我们上一代(Codex)模型的安全研究人员发现并披露了React中可能导致源代码暴露的漏洞。我相信这些模型对网络安全将产生净收益,但随着它们的改进,我们正处于‘真实影响阶段’。”
推出可信访问计划,为专业安全人员提供特殊权限
为平衡能力提升与安全风险,OpenAI针对网络安全能力的增强在模型层面和产品层面都增加了额外保护措施,包括针对有害任务和提示注入的专门安全训练、智能体沙箱以及可配置的网络访问。同时,公司正在进行仅限邀请的可信访问计划试点。
该计划最初仅向经过审查的安全专业人员和具有明确专业网络安全用例的组织开放。符合条件的参与者将获得使用OpenAI最强大模型进行防御性工作的权限,使其能够开展合法的双重用途工作,如漏洞研究或授权的红队测试,同时消除安全团队在模拟威胁行为者、分析恶意软件或压力测试关键基础设施时可能遇到的限制。
Altman在X上表示:“我们正在开始探索用于防御性网络安全工作的可信访问计划。”他还在另一条帖子中为Codex招聘打广告:“Codex变得极其出色,并将快速改进。如果你想帮助它在明年变得好100倍,团队正在招人。保证有疯狂的冒险,成功的可能性很大。”